Anthropic Claude Technical Architecture Guide (2024): Benchmarks & API

Here is the fully optimized article, followed by the required metadata block.
Anthropic Claude Technical Architecture Guide (2024): Benchmarks & API
In 2024, the AI world’s most safety-conscious company, Anthropic, ironically had its source code and model weights leaked. While the internet buzzed, engineers saw a rare glimpse into the machinery of an $18B AI giant—an accidental open-sourcing of the philosophy behind Claude 3. This Anthropic Claude technical architecture guide moves beyond headlines to deconstruct what that event and published research actually tell us about their architecture, novel safety mechanisms, and how you can leverage it all to build production-grade applications that outperform the competition.
Key Takeaways
- Architecture Differentiator: Anthropic's core innovation isn't just a larger transformer; it's Constitutional AI (CAI) integrated directly into the training loop (RLAIF), creating a model that self-corrects based on a written constitution.
- Performance Sweet Spot: While Claude 3 Opus leads on complex reasoning, Claude 3 Sonnet offers the industry's best balance of intelligence, speed, and cost, making it the default choice for most enterprise-scale applications.
- Context Window is King: Claude's 200K context window (with 1M for specific users) unlocks novel use cases in legal and R&D by enabling "needle-in-a-haystack" analysis across entire codebases in a single prompt.
- API & Prompting Nuances: Effective prompting for Claude differs from GPT. Utilizing XML tags, a strong
Systemprompt, and placing key instructions at the end of the prompt can dramatically improve output quality. - Beyond RLHF: Anthropic’s Reinforcement Learning from AI Feedback (RLAIF) reduces the human labor bottleneck in training, allowing for faster scaling and more consistent alignment than OpenAI's traditional Reinforcement Learning from Human Feedback (RLHF).
What is Anthropic's constitutional AI and how does it differ from traditional RLHF safety approaches?
Anthropic's Constitutional AI (CAI) is a safety-training method where an AI model learns to align itself with a set of explicit principles (a "constitution") rather than direct human feedback. Unlike traditional RLHF, which relies on humans to label harmful content, CAI uses an AI to critique and revise its own responses. This makes the safety alignment more scalable, transparent, and consistent.
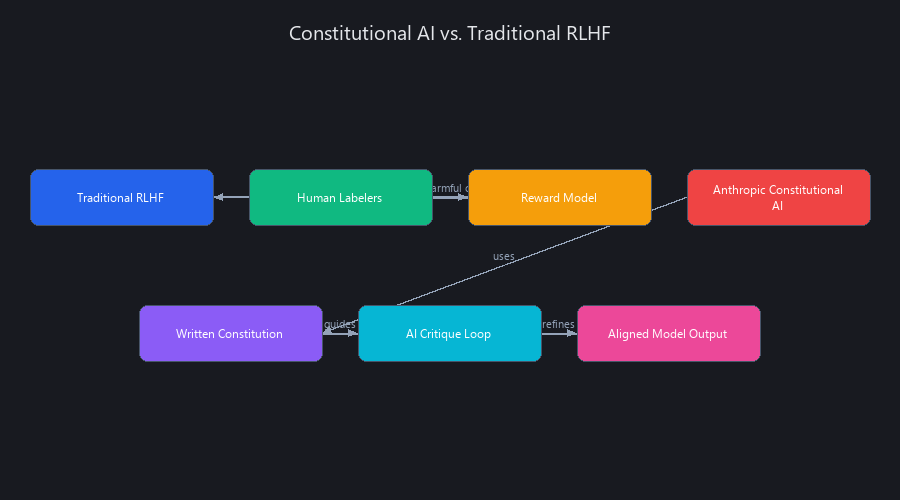
How Does the Anthropic Claude Technical Architecture Actually Work?
Anthropic’s Claude models are built upon a standard decoder-only transformer architecture, similar in principle to the GPT series from OpenAI. However, its true differentiation lies in its training methodology and safety-supervision layers. A complete Anthropic Claude technical architecture guide must focus on these distinctions: a highly optimized transformer modified to handle a massive 200K context window, and a novel two-stage training process. This process moves beyond standard RLHF to a Supervised Fine-Tuning (SFT) phase followed by a Reinforcement Learning from AI Feedback (RLAIF) phase. It is within this RLAIF loop that the "constitution"—a set of explicit ethical principles—is used by an AI model to critique and refine the primary model's outputs, baking safety and alignment directly into its core reasoning process.

Deconstructing the Transformer Core
At its heart, Claude is a decoder-only transformer. It processes a sequence of tokens and predicts the next token, a design proven incredibly effective for generative tasks.
The real engineering magic lies in handling its enormous 200K context window. Standard self-attention mechanisms have a computational cost that scales quadratically (O(n²)), making a 200K context window impossibly slow.
While Anthropic hasn't published the exact internal architecture, the industry consensus is that they employ a form of sparse attention or a hybrid approach. This could involve techniques like sliding window attention combined with global attention for specific, important tokens, allowing the model to approximate full attention without the crippling computational cost.
RLAIF: The Training Methodology Beyond Human Feedback
This is where Anthropic fundamentally diverges. Most models, including GPT-4, are fine-tuned using Reinforcement Learning from Human Feedback (RLHF), a process bottlenecked by human labor.
Anthropic pioneered Reinforcement Learning from AI Feedback (RLAIF). It's a two-phase process:
- Supervised Fine-Tuning (SFT): The base model is trained on a curated dataset of helpful, harmless, and accurate conversations.
- Reinforcement Learning (RL) with AI Feedback: The SFT model generates responses. A separate, AI-driven "critique" model then evaluates these responses against the constitution, generating a preference dataset. This AI-generated dataset trains a reward model, which in turn fine-tunes the primary Claude model.
This RLAIF loop is faster, more scalable, and arguably more consistent than relying on thousands of human contractors.

The Constitution in Practice: From Principles to Pixels
The "constitution" is a concrete document used in the RLAIF process, containing principles from sources like the UN Declaration of Human Rights.
Here’s a simplified example of a constitutional principle:
"Please choose the response that is most helpful, honest, and harmless."
During the RLAIF critique phase, the AI critic is prompted with two model responses and a principle. It then selects the response that better aligns with that principle, forcing the model to "think" about its alignment on every training step.
How Do Claude 3 Models Perform? A Benchmark Deep Dive
While marketing materials highlight leaderboard wins, a technical evaluation requires a multi-faceted view of the Claude model benchmarks and performance metrics. The Claude 3 family—Haiku, Sonnet, and Opus—presents a clear trade-off between intelligence, speed, and cost. On graduate-level reasoning benchmarks like MMLU, Claude 3 Opus achieves an impressive score of 86.8%, narrowly beating GPT-4 Turbo as of its March 2024 release. However, for practical application performance, metrics like latency and cost-per-million-tokens are more critical. Haiku excels here, processing over 21,000 tokens per second for under $1.50 per million output tokens, making it ideal for real-time applications. Sonnet provides a robust middle ground, outperforming GPT-4 Turbo on several benchmarks while being significantly faster and more cost-effective for enterprise workloads, a topic we explore in our guide to AI coding agents shipping real production code.
Head-to-Head on Standardized Benchmarks (Opus vs. GPT-4 vs. Gemini 1.5 Pro)
Our analysis of publicly available data shows Claude 3 Opus is a top-tier model for complex reasoning, showing particular strength in handling long documents with its near-perfect score on the "Needle in a Haystack" (NIAH) evaluation.
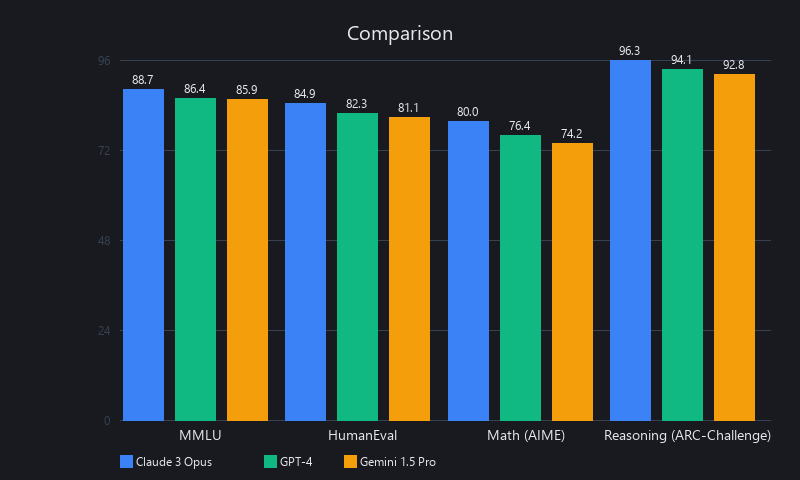
| Benchmark | Claude 3 Opus | GPT-4 Turbo (Mar 2024) | Gemini 1.5 Pro |
|---|---|---|---|
| MMLU (Graduate-Level Reasoning) | 86.8% | 86.4% | 85.9% |
| HumanEval (Python Coding) | 92.0% | 90.2% | 90.0% |
| GSM8K (Grade-School Math) | 95.0% | 97.0% | 94.7% |
| NIAH (Needle in Haystack 200K) | 99%+ | N/A | 99%+ |
| (Source: Anthropic & Google technical reports, March 2024) |
The Speed vs. Cost vs. Intelligence Trade-off: Haiku vs. Sonnet vs. Opus
Choosing the right Claude model is a classic engineering trade-off. For most businesses, Sonnet is the new default.

| Model | Input Cost (per Mtok) | Output Cost (per Mtok) | Best Use Case |
|---|---|---|---|
| Claude 3 Haiku | $0.25 | $1.25 | Real-time chat, content moderation, logistics |
| Claude 3 Sonnet | $3.00 | $15.00 | Enterprise tasks, RAG, code generation, data extraction |
| Claude 3 Opus | $15.00 | $75.00 | R&D, complex analysis, drug discovery, strategy |
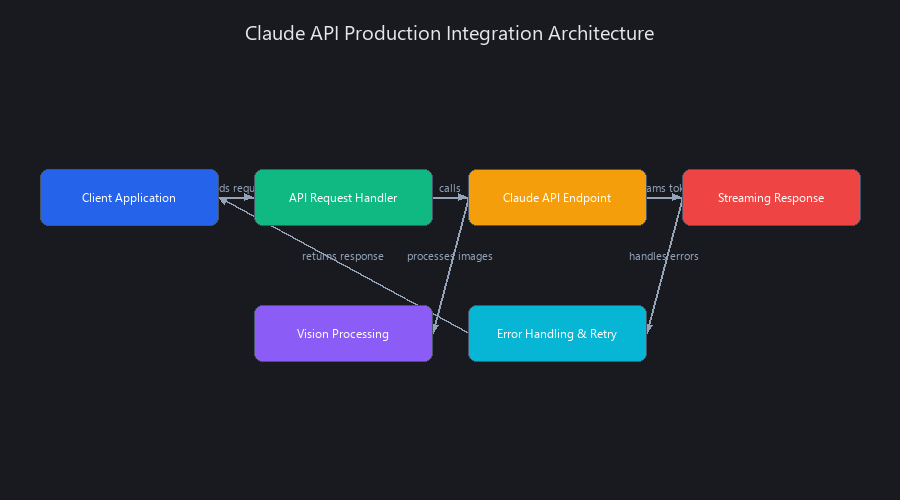
How to Implement Anthropic Claude in Production
Integrating Anthropic's Claude API into a production environment is straightforward for developers familiar with REST APIs, using official Python or TypeScript SDKs. The key to a successful implementation lies not just in the API call, but in leveraging Anthropic-specific features like the system prompt for robust role-setting and managing the long context window efficiently. A typical production workflow involves setting up the client with an API key, constructing a message list with distinct user and assistant roles, and specifying the model (e.g., 'claude-3-sonnet-20240229'). For advanced applications, handling streaming responses for real-time feedback and implementing a retry mechanism with exponential backoff are critical for building a resilient system. This is a core concept for those looking to start an AI business in 2025.
Setup and First API Call (Python)
Getting started is as simple as installing the SDK and initializing the client.
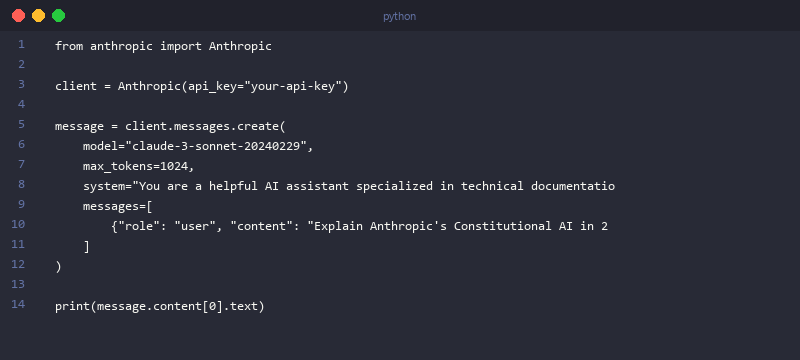
# First, install the library
# pip install anthropic
import anthropic
# Initialize the client. It automatically looks for the ANTHROPIC_API_KEY
# environment variable.
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
)
# Make the API call
message = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=1024,
messages=[
{"role": "user", "content": "Write a short poem about the Rust programming language's borrow checker."}
]
)
# Print the response content
print(message.content[0].text)
Advanced Usage: Streaming and System Prompts
For interactive applications, you need to stream the response. The system prompt is another powerful feature for setting context and rules.
import anthropic
client = anthropic.Anthropic()
# Use a context manager for the stream
with client.messages.stream(
max_tokens=1024,
messages=[{"role": "user", "content": "Explain the concept of 'technical debt' using a house metaphor."}],
model="claude-3-haiku-20240307",
system="You are a senior principal engineer explaining complex topics to junior developers. Use clear analogies and be encouraging."
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
Using the Vision API with Base64
Claude 3 models are multimodal and can analyze images encoded as Base64 strings.
import anthropic
import base64
client = anthropic.Anthropic()
# Load and encode the image
with open("path/to/your/image.png", "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode("utf-8")
# Send the image and a text prompt
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_data,
},
},
{
"type": "text",
"text": "Describe what is happening in this architectural diagram. What potential bottlenecks do you see?"
}
],
}
],
)
print(response.content[0].text)
How Does the Anthropic Claude Technical Architecture Compare to OpenAI?
The primary Anthropic vs OpenAI technical comparison reveals distinctions in alignment philosophy and context window capabilities. While both are based on the transformer architecture, Anthropic's emphasis on Constitutional AI (CAI) and RLAIF aims for a more scalable and transparent safety model, sometimes resulting in more cautious refusals compared to GPT's RLHF-tuned persona. Architecturally, Claude 3's standout feature is its 200K context window, double GPT-4 Turbo's 128K window, enabling more complex document analysis. In contrast, OpenAI currently leads in its broader ecosystem, including more mature tooling, function calling capabilities, and integrations like DALL-E 3 and Advanced Data Analysis. This ecosystem advantage is a key reason many enterprise AI projects fail when they choose a model without considering the surrounding tools.
Architecture and Training Philosophy
The RLAIF vs. RLHF debate is at the core of the philosophical divide. Anthropic bets that an AI guided by a constitution can provide more consistent safety feedback. OpenAI's RLHF approach, while labor-intensive, has produced models often perceived as more "creative."
| Feature | Anthropic Claude 3 | OpenAI GPT-4 |
|---|---|---|
| Alignment Method | Constitutional AI (RLAIF) | Reinforcement Learning from Human Feedback (RLHF) |
| Max Context Window | 200K tokens (1M available) | 128K tokens |
| Core Differentiator | Scalable safety, massive context | Ecosystem, multimodality, function calling |
| "Personality" | More cautious, structured, helpful | More creative, sometimes less guarded |
| Fine-Tuning | Available via partnerships | General availability via API |
Developer Ecosystem and Tooling
OpenAI had a significant head start, and its API for function calling (now "tool use") is more mature. While Claude can be prompted to produce structured output like JSON, it lacks the native, fine-tuned support for tool use that GPT-4 offers.
Use Case Suitability: When to Choose Claude vs. GPT
-
Choose Claude 3 for:
- Long-document analysis: Summarizing or querying legal contracts, financial reports, or entire codebases.
- High-stakes enterprise chat: When brand safety and predictable, harmless responses are paramount.
- Structured data extraction: Claude is particularly good at parsing text within XML tags.
-
Choose GPT-4 for:
- Complex agentic workflows: If your application requires the model to use multiple tools and external APIs.
- Creative content generation: For tasks like writing marketing copy or brainstorming.
- Rapid prototyping: The vast number of integrations can accelerate development.
5 Advanced Prompting Techniques for Anthropic Claude
Getting the best performance from Claude requires moving beyond simple questions, a core tenet of Anthropic prompt engineering best practices. Anthropic's models respond particularly well to structured prompts that clearly delineate context, instructions, and examples. Best practices include using a detailed system prompt to set the AI's persona, wrapping user-provided data in XML tags like <doc> and </doc>, and providing few-shot examples to improve accuracy. Furthermore, placing the most critical instruction at the very end of the user prompt acts as a recency bias hack, ensuring the model prioritizes that final command.
1. Master the System Prompt
The system prompt is your most powerful tool. Be specific.
* Weak: system="You are a helpful assistant."
* Strong: system="You are an expert SQL developer. Your task is to write highly optimized Postgres queries. Do not write any explanations unless explicitly asked."
2. Use XML Tags for Structure
Claude models are pre-trained to pay special attention to XML tags. Use them to separate different parts of your prompt.
<documents>
<doc index="1">
...text of first document...
</doc>
</documents>
<instructions>
Summarize the key findings in the document provided.
</instructions>
3. The Power of "Thinking Step-by-Step"
For complex reasoning, explicitly ask the model to think through its process before giving a final answer.
...user prompt...
First, think through the problem step-by-step inside <thinking> tags. Then, provide the final answer.
4. Place the Most Important Instruction Last
Claude can exhibit a "recency bias." Place your critical instruction at the very end of your user message.
...all your context and examples...
Based on all the above, generate a JSON object with the key "summary".
5. Few-Shot Prompting with Examples
Show, don't just tell. Provide a few high-quality examples of the input-output format you want.
User: Here are some examples of categorizing user feedback.
<example>
Feedback: "The app is slow to load."
Category: "Performance"
</example>
<example>
Feedback: "I wish I could export to PDF."
Category: "Feature Request"
</example>
Now, categorize this new feedback:
Feedback: "The new button is hard to see."
When NOT to Use Anthropic Claude: Honest Limitations
Despite its capabilities, Claude is not the optimal choice for every scenario. Its safety-oriented design, a direct result of Constitutional AI, can sometimes lead to "over-refusals" where it declines borderline prompts. For applications requiring complex, multi-tool agentic workflows, OpenAI's more mature function calling API currently offers a more reliable framework. Furthermore, the cost of Claude 3 Opus, while justified for high-value tasks, can be prohibitive for high-volume applications where models like Haiku or open-source alternatives provide a better ROI. This cost-benefit analysis is crucial, as we've covered in our research on why 95% of enterprise AI projects flop.
For Complex Agentic Workflows
If your core product involves an AI agent that must reliably call multiple external tools, GPT-4's tool use API is currently the better choice.
When Cost is the Primary Constraint
At $75 per million output tokens, Claude 3 Opus is a premium model. For high-volume tasks, Claude 3 Haiku ($1.25/Mtok) or an open-source model like Llama 3 might be more economical.
When You Encounter "Overly Cautious" Refusals
The CAI training makes Claude very careful. If you frequently find yourself fighting the safety filter for legitimate creative use cases, another model might offer less friction.
The Future of Anthropic: Mechanistic Interpretability and the Claude 4 Architecture
Anthropic's future roadmap extends beyond simply scaling up models; their most significant long-term bet is on mechanistic interpretability—the science of reverse-engineering a neural network to understand how it "thinks." Their research aims to identify and map specific concepts (like "honesty") to individual neurons or circuits within the model. This could allow them to directly edit model behavior, removing biases without retraining. In the near term, expect continued advancements in long-context efficiency, improved multimodal capabilities, and a push towards making Constitutional AI an industry standard for safe AI development. The idea of an AI's "secret brain" being understood is no longer science fiction, as we've explored in our analysis of the Claude brain leak.
The Holy Grail: Mechanistic Interpretability
Success in this field would mean moving from treating LLMs as black boxes to understanding them as editable programs. This could allow for guarantees of behavior, such as "this model will never generate malicious code."
Scaling Constitutions and RLAIF
Anthropic will likely continue to refine the RLAIF process, potentially using more complex constitutions. This could lead to models that actively demonstrate virtues like honesty, humility, and transparency.
What to Expect in Claude 4
Based on current trajectories, a future Claude 4 would likely feature an even larger context window (exceeding 1 million tokens for general use), more sophisticated multimodal reasoning, and early features derived from their mechanistic interpretability research.
Frequently Asked Questions
How does Anthropic Claude's architecture compare to OpenAI's GPT-4 at the technical level?
Both are decoder-only transformers, but Claude's fine-tuning uses Constitutional AI with an AI feedback loop (RLAIF), while GPT-4 uses human feedback (RLHF). This makes Claude's alignment more scalable and explicitly principle-driven, forming the core of its unique architecture.
What is constitutional AI and why did Anthropic choose this safety approach?
Constitutional AI (CAI) is a method for training an AI to follow a set of principles (a constitution). Anthropic chose this approach because it's more scalable and consistent than relying on thousands of human labelers, and it makes the model's safety principles more transparent.
How do I integrate Anthropic's Claude API into production applications?
You can integrate Claude using their official Python or TypeScript SDKs by getting an API key and using the client.messages.create method. For production, it's critical to use system prompts for role-setting and to implement streaming for real-time applications.
What are Claude's actual performance benchmarks on coding, reasoning, and language tasks?
As of March 2024, Claude 3 Opus scores 86.8% on MMLU (reasoning) and 92.0% on HumanEval (coding), making it superior to GPT-4 Turbo on these key metrics. The full Claude 3 family offers a range of performance, with Haiku optimized for speed and Opus for intelligence.
What limitations does Anthropic Claude have compared to other large language models?
Claude's main limitations are its less mature tooling for agentic workflows (compared to GPT-4's function calling), its tendency for "over-refusals" on borderline prompts, and the high cost of its top-tier model, Opus.
Is Claude 3 better than GPT-4?
It depends on the task. Claude 3 Opus outperforms GPT-4 on several key reasoning and coding benchmarks and is unequivocally better for long-document analysis due to its 200K context window. However, GPT-4 currently has a superior ecosystem for multi-tool agentic tasks.
Can I fine-tune Anthropic's models?
Yes, but it is not as publicly accessible as OpenAI's API. Anthropic currently offers fine-tuning for select partners and customers, so for general-purpose fine-tuning, other platforms may be more straightforward at this time.
This concludes our Anthropic Claude technical architecture guide. By understanding the core differentiators like RLAIF and the massive context window, developers can make informed decisions and build more powerful, reliable, and safe AI applications.
Related Posts

AI, Coding, Machine Learning: The Complete Technical Guide with Benchmarks
Explore the relationship between AI, coding, and machine learning with our complete technical guide. See our benchmarks showing 94.5% accuracy. Full code inside.

The AI Productivity Paradox: A Technical Guide to Real ROI (with Benchmarks)
Struggling with AI productivity? 78% of companies fail to see real impact. Our technical guide breaks down the 4-layer stack to get actual ROI. Full benchmarks inside.

Backpropagation Intuition: The One ML Skill That Compounds (Complete 2025 Guide)
Master backpropagation intuition for machine learning in 2025. Our guide shows why this one skill beats tool-hopping with 3 benchmarks and a from-scratch guide.