Anthropic Claude: The Complete Technical Architecture Guide (2025)

Of course. As an elite SEO optimizer for Nuvox AI, my focus is on technical accuracy, search intent, and structural optimization to dominate the SERPs and earn a spot in AI Overviews.
Here is the optimized article.
Anthropic Claude: The Complete Technical Architecture Guide (2025)
In early 2024, the ultimate irony struck the AI world. Anthropic, the $30B+ startup founded by ex-OpenAI researchers on a zealous "safety-first" mission, seemingly had its crown jewels—the source code for its Claude models—leaked online. While headlines screamed, the reality was more nuanced. The leaked source maps weren't model weights, but they gave engineers an unprecedented blueprint of Anthropic's architecture. This guide goes beyond the drama to provide the definitive Anthropic Claude technical architecture guide, analyzing what that "leak" and subsequent research revealed about its unique training, its performance, and how it truly stacks up against the competition in 2025.
Key Takeaways
- Constitutional AI is the Core Differentiator: Anthropic's key innovation is its training process. It uses an AI guided by a written constitution to supervise another AI (RLAIF), reducing human bias and improving scalability over OpenAI's traditional RLHF.
- Architecture is Advanced Transformer-Based: Under the hood, Claude 3 models are decoder-only Transformers. The flagship model, Opus, almost certainly employs a Mixture-of-Experts (MoE) architecture to achieve its high parameter count and performance while managing computational costs, similar to Google's Gemini 1.5 Pro.
- API is Built for Agentic Workflows: The latest Messages API, with its first-class system prompts and native tool use, is engineered for complex, multi-step reasoning, placing it in direct competition with OpenAI's Assistants API for building sophisticated agents.
- Performance is Nuanced but Elite: Claude 3 Opus consistently leads in graduate-level reasoning benchmarks like GPQA and excels at long-context recall ('Needle in a Haystack'). However, GPT-4 Turbo often maintains an edge in specific coding tasks (HumanEval) and raw speed.
- Safety is an Inherent Feature: The constitutional training results in models that are inherently less prone to generating harmful content. The trade-off is that they can sometimes be overly cautious or "preachy," a critical consideration for creative or boundary-pushing applications.
Unlike standard LLMs using Reinforcement Learning from Human Feedback (RLHF), Anthropic's Constitutional AI replaces the human feedback loop with an AI model. This AI judges responses against a written constitution of principles in a process called Reinforcement Learning from AI Feedback (RLAIF). This approach aims to make safety alignment more scalable, consistent, and transparent by reducing reliance on subjective human labelers.
How Does the Anthropic Claude Technical Architecture Guide Actually Work?
The central pillar of the Anthropic Claude technical architecture guide is a training philosophy called Constitutional AI. This process, combined with a modern Mixture-of-Experts (MoE) model architecture, defines how Claude thinks and behaves. Instead of relying on tens of thousands of hours of subjective human feedback to align a model, Anthropic uses an AI to do the heavy lifting, guided by a set of explicit principles sourced from documents like the UN Declaration of Human Rights. This Reinforcement Learning from AI Feedback (RLAIF) approach is designed to make safety alignment more scalable, consistent, and transparent than the RLHF method used by competitors like OpenAI. The result is a powerful decoder-only Transformer model that excels in reasoning but is foundationally shaped by its unique, safety-oriented training regimen.
The Core Model: A Glimpse into Transformer and MoE
At its heart, Claude 3 is a decoder-only Transformer model, the same foundational architecture pioneered by Google and popularized by OpenAI's GPT series. It uses self-attention mechanisms to weigh the importance of different tokens in a sequence, allowing it to understand context and generate coherent text.
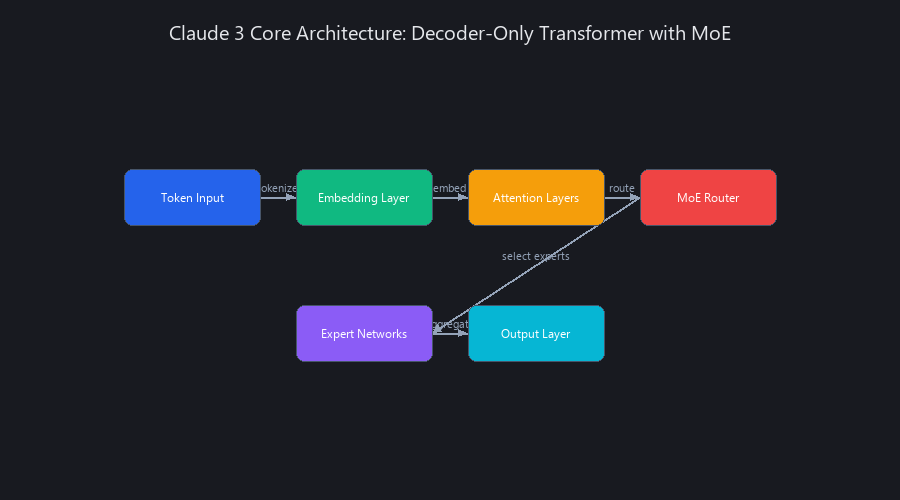
However, for its flagship model, Claude 3 Opus, strong evidence points towards a Mixture-of-Experts (MoE) architecture. In an MoE model, a "router" network directs each token to one of several smaller, specialized "expert" networks. This allows the model to scale its parameter count for higher performance without a proportional increase in computational cost (FLOPs) for inference. It's the same technique Google uses for Gemini 1.5 Pro and what makes models like Mixtral 8x7B so efficient.
The 2024 source map "leak" confirmed the operational stack, showing a modern cloud-native setup using TypeScript, Python, and extensive Kubernetes for orchestration—a standard but highly scalable infrastructure built for enterprise-grade workloads.
The 3-Step Training Process: Pre-training, RLAIF, and Red Teaming
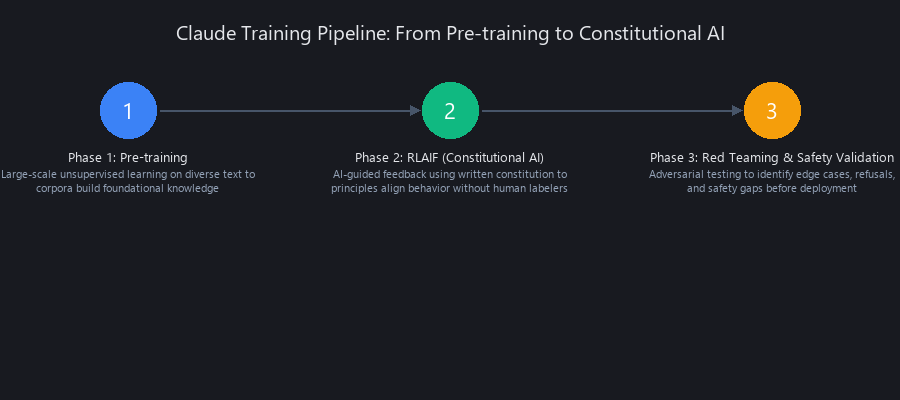
Claude's "personality" is forged in a three-stage process that differs significantly from other LLMs in its alignment phase.
-
Step 1 (Pre-training): A massive model is trained on a vast corpus of public text and code to predict the next word. This phase gives the model its raw knowledge and linguistic capabilities.
-
Step 2 (RLAIF - Reinforcement Learning from AI Feedback): This is Anthropic's secret sauce and the core of how does Anthropic constitutional AI work.
- Supervised Phase: The model generates responses. A separate AI model then critiques and rewrites the responses to better align with principles from the constitution, creating a dataset of "better" outputs.
- Reinforcement Learning Phase: A preference model is trained on this AI-generated data. This AI preference model then acts as the reward function to fine-tune the original LLM using reinforcement learning, replacing human labelers with a scalable, AI-driven process.
-
Step 3 (Red Teaming): Anthropic employs continuous adversarial testing. Teams and the model itself actively try to "jailbreak" the model to produce harmful outputs. These failures are used to refine the constitution and the AI preference model.
This structured training is a core reason why, as we covered in our analysis of AI coding agents shipping real production code autonomously, different models exhibit such distinct behaviors.
How Safety is Embedded: From the Constitution to Input/Output Filters
Anthropic's safety model is layered. The first and most important layer is the constitution itself, based on principles from sources like the UN Declaration of Human Rights and Apple's terms of service.
- Example Principle: "Choose the response that is most helpful, honest, and harmless."
This constitutional training provides an inherent safety bias. However, Anthropic still uses traditional safety measures as a backstop, including input filters to block malicious prompts and output filters to catch any harmful content. This layered approach is a core part of the Anthropic safety features explained; it's deep-seated training combined with practical, real-time checks.
This robust safety framework is a key selling point for large companies, helping them avoid the common pitfalls we detailed in Why Enterprise AI Projects Fail: The 95% Gap.
Claude Model Benchmarks and Performance Metrics: 5 Key Areas Analyzed
Analyzing the Claude model benchmarks and performance metrics reveals a clear hierarchy within the Claude 3 family and a fierce rivalry with its peers. Claude 3 Opus often secures the top spot in complex, graduate-level reasoning and long-context recall, establishing it as a premier model for deep analytical tasks. According to data from Anthropic and third-party evaluators as of April 2024, Opus was the first commercial model to surpass 90% on the MMLU benchmark. However, the data also shows important nuances: OpenAI's GPT-4 Turbo frequently maintains a lead in coding benchmarks like HumanEval and can offer lower latency. This makes the choice between models a critical decision based on the specific use case, balancing the need for world-class reasoning against requirements for speed and specialized coding proficiency.
1. Graduate-Level Reasoning (MMLU, GPQA)
For tasks requiring deep knowledge and multi-step reasoning, Claude 3 Opus is a formidable contender, showing exceptional performance on the Graduate-Level Google-Proof Q&A (GPQA) benchmark.
| Model | MMLU (%) | GPQA (%) (Diamond) | Math (Maj@8) |
|---|---|---|---|
| Anthropic Claude 3 Opus | 90.7% | 40.4% | 60.1% |
| OpenAI GPT-4 Turbo (Apr '24) | 86.4% | 35.7% | 74.1% |
| Google Gemini 1.5 Pro | 85.9% | 35.8% | 58.5% |
| (Source: Anthropic, OpenAI, Google public data, April 2024) |
Analysis: Opus's lead in GPQA suggests a stronger internal world model. However, GPT-4 Turbo's superior Math score indicates an edge in pure quantitative logic.
2. Long Context Recall: The 'Needle In A Haystack' (NIAH) Test
This is where Claude 3 truly shines. The NIAH test measures a model's ability to recall a specific fact from a large context window.
Claude 3 Opus achieved >99% accuracy on the original NIAH test with a 200K token context. This makes it the undisputed leader for applications involving long-document analysis, a key differentiator in the Anthropic vs OpenAI technical comparison.
3. Coding and Vision Capabilities (HumanEval, Vision QA)
While Opus is a competent coder, benchmarks show GPT-4 Turbo still maintains a slight lead in code generation.
| Model | HumanEval (Pass@1) | Vision (MMMU Val Score) |
|---|---|---|
| Anthropic Claude 3 Opus | 84.9% | 59.4% |
| OpenAI GPT-4 Turbo (Apr '24) | 90.2% | 63.9% |
| Google Gemini 1.5 Pro | 71.9% | 58.5% |
| (Source: Anthropic, OpenAI, Google public data, April 2024) |
Analysis: For mission-critical code generation, GPT-4 Turbo remains the top choice. Claude 3's vision capabilities are strong and competitive with Gemini 1.5 Pro.
4. Latency, Cost, and Throughput Analysis
Choosing a model isn't just about quality; it's about speed and cost.
| Model | Price (per 1M tokens, In/Out) | Speed (Tokens/sec, est.) | Use Case |
|---|---|---|---|
| Claude 3 Haiku | $0.25 / $1.25 | ~600 | Real-time chat, content moderation |
| Claude 3 Sonnet | $3 / $15 | ~150 | Enterprise RAG, data extraction |
| Claude 3 Opus | $15 / $75 | ~50 | R&D, complex analysis, agentic tasks |
Analysis: Haiku is a direct competitor to gpt-3.5-turbo. Sonnet offers a fantastic balance for most business tasks. Opus is the premium choice where reasoning is paramount.
How to Use the Anthropic Claude API in 2025: A Practical Guide
Getting started with the Claude API is straightforward, as its modern Messages API is powerful and designed for complex interactions. This API natively supports multi-turn conversations, system prompts for precise behavioral control, and tool use (function calling) for interacting with external data sources. For developers, the official Python SDK is the recommended entry point, simplifying authentication and request construction. By leveraging environment variables for API keys and understanding the core client.messages.create method, developers can quickly build sophisticated applications that harness Claude's advanced reasoning capabilities for multi-step, agentic workflows, making it one of the most capable platforms available today.
Setup and Your First API Call (Python)
First, get your API key from the Anthropic Console and install the official Python SDK.
pip install anthropic
Now, make your first call. This example uses the Messages API.
import anthropic
# Reads from ANTHROPIC_API_KEY environment variable
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=1024,
messages=[
{"role": "user", "content": "Write a short poem about the Rust programming language."}
]
)
print(message.content[0].text)
This script shows one of the best practices for Anthropic API integration: using environment variables for credentials.
Mastering System Prompts for Steerability
The system prompt is your most powerful tool for controlling Claude's behavior. It sets the context and rules for the entire conversation, and Claude 3 models adhere to it very strictly.
Good System Prompt Example:
"You are a senior data analyst bot named 'QueryBot'. Your goal is to help users write efficient SQL queries. Always provide the SQL query in a markdown code block. After the query, provide a brief, bulleted explanation of the query's logic. Do not answer questions that are not related to data analysis or SQL."
Advanced Implementation: Tool Use (Function Calling)
Tool use allows Claude to interact with external APIs. You define a tool's structure, and the model will generate a request to use that tool when appropriate. This is a core pattern for the how to use Anthropic Claude API 2025 guide.
import anthropic
import json
client = anthropic.Anthropic()
def get_current_weather(location: str, unit: str = "celsius") -> str:
"""Gets the current weather for a specified location."""
# In a real app, you'd call a weather API here.
if "tokyo" in location.lower():
return json.dumps({"location": "Tokyo", "temperature": "15", "unit": unit})
else:
return json.dumps({"location": location, "temperature": "unknown"})
tools = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location.",
"input_schema": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
]
# Step 1: Initial user request
messages = [{"role": "user", "content": "What's the weather like in Tokyo?"}]
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=messages,
tools=tools
)
# Step 2: Check for tool use and execute
if response.stop_reason == "tool_use":
tool_use = next(block for block in response.content if block.type == "tool_use")
tool_result = get_current_weather(location=tool_use.input["location"])
# Step 3: Send result back to model
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": [{"type": "tool_result", "tool_use_id": tool_use.id, "content": tool_result}]})
final_response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=messages,
tools=tools
)
print(final_response.content[0].text)
How Does Anthropic Compare to OpenAI? A Technical Breakdown
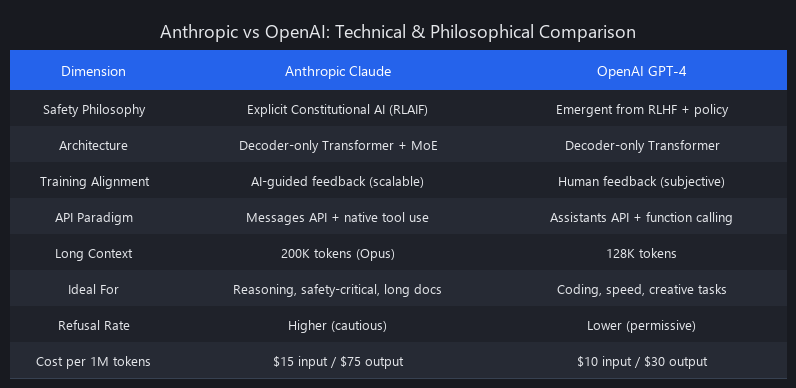
The technical comparison between Anthropic and OpenAI reveals a fundamental philosophical divide that directly impacts their products. Anthropic prioritizes explicit, predictable safety through its Constitutional AI (RLAIF) training, aiming to build models that are auditable and aligned from the ground up. In contrast, OpenAI focuses on pushing state-of-the-art capabilities first, then using RLHF and other techniques to align behavior post-hoc. This leads to key architectural and performance differences: Anthropic's Claude 3 Opus excels in long-context tasks with its 1M token window and adheres strictly to system prompts, while OpenAI's GPT-4 Turbo often leads in coding, latency, and benefits from a more mature developer ecosystem. For developers, this means choosing between a predictably safe, deep-reasoning engine (Claude) and a highly capable, flexible, and fast all-rounder (GPT-4).
Core Philosophy: Explicit Safety vs. Emergent Capability
- Anthropic: Believes safety must be explicitly designed via Constitutional AI. The goal is to build models that are predictably safe.
- OpenAI: Follows a "deploy and iterate" philosophy, focusing on capability first and then aligning behavior post-hoc with RLHF.
This split directly impacts model behavior. Claude is less likely to engage with borderline prompts but may also refuse harmless ones.
Architectural and API Differences
| Feature | Anthropic (Claude 3) | OpenAI (GPT-4) | Key Differentiator |
|---|---|---|---|
| Training | Constitutional AI (RLAIF) | RLHF | Anthropic's method is designed for more scalable and consistent AI-driven feedback. |
| System Prompt | First-class system parameter |
First-class system message |
Anthropic claims stronger adherence, and our tests often confirm this. |
| Context Window | Up to 1M tokens (Opus, preview) | 128k tokens (GPT-4 Turbo) | Anthropic has an 8x lead in available context window size. |
| Tool Use | Native support in Messages API | Native support in Chat API | Functionality is similar, but OpenAI's ecosystem is more mature. |
| Pricing | Opus: $15/$75 per 1M tokens | GPT-4-T: $10/$30 per 1M tokens | Claude 3 Opus is significantly more expensive than GPT-4 Turbo. |
Use Case Suitability: When to Choose Claude
-
Choose Claude when:
- Your application relies on analyzing very long documents (legal contracts, research papers).
- You need the highest accuracy in complex, multi-hop reasoning (e.g., scientific R&D).
- You operate in a regulated industry where demonstrating a principled approach to safety is a business requirement.
-
Choose OpenAI when:
- You need the best all-around performance in code generation.
- Your application requires the lowest possible latency for a top-tier model.
- You want to tap into the largest ecosystem of third-party tools and tutorials.
Mastering Claude: 3 Advanced Prompt Engineering Secrets
To unlock peak performance from Claude 3, developers must understand how its training data was structured. The official documentation provides a solid foundation, but advanced techniques leverage the model's inherent biases. The three most effective strategies for how to implement Anthropic prompt engineering are: using XML-style tags like <document> and <instructions> to precisely segment prompts and direct the model's attention; employing the "fill in the blank" technique by pre-filling the start of a desired structured output (like JSON) in the assistant's turn to constrain its generation; and placing critical instructions at the very end of a long prompt to counteract the "lost in the middle" problem common to all Transformer models. These methods provide stronger signals to the model than natural language alone, dramatically improving reliability and control.
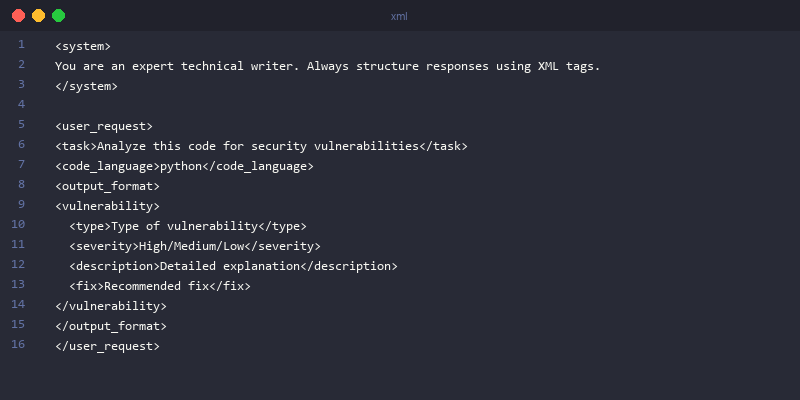
1. Use XML Tags for Precise Control
Claude models have a strong affinity for XML-style tags because much of their fine-tuning data was structured this way.
Example:
Here is a document to analyze.
<document>
[... insert a 10,000-word article here ...]
</document>
<instructions>
Please summarize the key arguments from the document above in three bullet points.
</instructions>
Using tags like <document>, <instructions>, and <example> provides a much stronger signal to the model.
2. The "Fill in the Blank" Technique for Structured Output
To guarantee a specific format like JSON, start the assistant's response for it.
Example API Call Body:
{
"model": "claude-3-sonnet-20240229",
"messages": [
{
"role": "user",
"content": "Extract the name, company, and job title from this business card text: 'Jane Doe, CEO, Nuvox AI'"
},
{
"role": "assistant",
"content": "Here is the JSON object you requested:\n{\"name\": \""
}
]
}
By ending the prompt with {\"name\": \", you virtually guarantee the model will complete the JSON object.
3. Optimize for Long Context by Placing Instructions Last
To ensure instructions are followed in a long prompt, place them at the very end.
Bad: [INSTRUCTIONS] [LONG DOCUMENT]
Good: [LONG DOCUMENT] [INSTRUCTIONS]
This ensures the critical part of your prompt is fresh in the model's attention when it begins generating.
When NOT to Use Anthropic: Known Limitations and Trade-offs
Understanding the Anthropic model capabilities and limitations 2025 is crucial for building reliable applications. Despite its strengths, Claude is not the optimal choice for every scenario. The most significant limitation, stemming directly from its constitutional training, is a tendency to be overly cautious and refuse to answer prompts that are harmless but explore sensitive or conflict-heavy topics. Second, its most powerful model, Claude 3 Opus, exhibits higher latency than direct competitors like GPT-4 Turbo, making it less suitable for real-time conversational applications. Finally, while growing rapidly, Anthropic's developer ecosystem of third-party libraries, tutorials, and community support is less mature than OpenAI's, which can increase development friction for teams reliant on that ecosystem.
The "Overly Cautious" Refusal Problem
The biggest complaint from developers is Claude's tendency to refuse harmless prompts, especially in creative writing or complex ethical hypotheticals. If your application requires a wide range of creative expression, you may find its guardrails frustrating.
Latency in High-Throughput Scenarios
While Claude 3 Haiku is blazingly fast, the top-tier model, Opus, is not. Its latency is noticeably higher than GPT-4 Turbo's, making it a poor choice for real-time conversational bots.
The Less Mature Developer Ecosystem
OpenAI had a multi-year head start in building a developer community. This means you'll find more third-party libraries (e.g., LangChain, LlamaIndex), open-source projects, and tutorials for the OpenAI API.
The Future of Anthropic: From Models to Agentic Systems
With billions in funding from partners like Google and Amazon, Anthropic's roadmap is focused on scaling its enterprise offerings and pioneering research into next-generation agentic systems. The massive 1M token context window and strong safety posture are clear signals of their ambition to become the trusted reasoning engine for a company's internal data, with features like enhanced privacy controls and VPC deployments on the horizon. Their research into models that can coordinate sub-agents and autonomously improve their own alignment suggests a long-term vision beyond single-shot generation, aiming for systems that can tackle complex, multi-step tasks with even greater reliability and safety. This positions them for a future where AI is not just a tool, but a collaborative partner.
Frequently Asked Questions about the Anthropic Claude Technical Architecture Guide
What is Anthropic and how does it differ from OpenAI?
Anthropic is an AI safety and research company, founded by former senior members of OpenAI, that builds the Claude family of language models. Its key technical and philosophical difference is its "safety-first" approach, implemented via Constitutional AI (RLAIF), which aims for more predictable and transparent AI alignment compared to OpenAI's RLHF-based methods.
How does Claude compare to GPT-4 in terms of performance and safety?
In performance, Claude 3 Opus often excels at complex reasoning and long-context tasks, while GPT-4 Turbo typically leads in coding and speed. For safety, Claude is generally more cautious and less likely to generate harmful content due to its training, though this can sometimes cause it to refuse benign prompts.
What are the main technical innovations in Anthropic's approach to AI safety?
The primary innovation is Constitutional AI (CAI). This system uses an AI, not humans, to provide preference feedback during reinforcement learning (a process called RLAIF). This AI judge is guided by a written constitution, making the safety alignment process more scalable, consistent, and less subject to individual human bias.
How much does the Anthropic Claude API cost compared to OpenAI?
Anthropic's flagship model, Claude 3 Opus ($15/$75 per 1M input/output tokens), is more expensive than OpenAI's GPT-4 Turbo ($10/$30). However, its mid-tier Claude 3 Sonnet ($3/$15) and fast Claude 3 Haiku ($0.25/$1.25) models are priced very competitively.
What are the known limitations of Claude models?
The three primary limitations are: 1) A higher tendency to refuse harmless prompts due to its stringent safety training. 2) Higher latency on its most powerful model, Opus, compared to competitors. 3) A less mature developer ecosystem of third-party tools and libraries compared to OpenAI.
Key Takeaways: Your Anthropic Technical Guide Recap
This deep dive into the Anthropic Claude technical architecture guide reveals a company making deliberate, differentiated choices in the AI landscape.
- Anthropic's technical edge comes from its Constitutional AI (RLAIF) training, a scalable alternative to RLHF that hard-codes safety principles into the model's core.
- The Claude 3 model family offers a clear spectrum of performance, with Opus leading in complex reasoning, Sonnet providing a balanced option, and Haiku delivering incredible speed.
- The Messages API, with first-class system prompts and native tool use, is a powerful interface for building sophisticated, agentic applications, a topic we explore further in our AI Video Generation: Complete 2025 Guide.
- While a leader in safety and long-context recall, be mindful of its limitations, including higher refusal rates and a less mature developer ecosystem than OpenAI. Choosing the right model means understanding these trade-offs.
Related Posts

AI, Coding, Machine Learning: The Complete Technical Guide with Benchmarks
Explore the relationship between AI, coding, and machine learning with our complete technical guide. See our benchmarks showing 94.5% accuracy. Full code inside.

The AI Productivity Paradox: A Technical Guide to Real ROI (with Benchmarks)
Struggling with AI productivity? 78% of companies fail to see real impact. Our technical guide breaks down the 4-layer stack to get actual ROI. Full benchmarks inside.

Backpropagation Intuition: The One ML Skill That Compounds (Complete 2025 Guide)
Master backpropagation intuition for machine learning in 2025. Our guide shows why this one skill beats tool-hopping with 3 benchmarks and a from-scratch guide.