Claude AI Complete Guide 2026: Everything You Need to Know

Anthropic just hit a $380 billion valuation. Enterprises are switching from ChatGPT. And Claude is quietly becoming the default AI for serious engineering work. Here's everything that matters.
Key Takeaways: Claude AI in 2026
- Claude 4.5 Sonnet dominates coding benchmarks with a 77.2% SWE-bench Verified score — Claude Opus 4.5 pushed past 80% — outperforming GPT-4 Turbo by a meaningful margin
- Enterprise adoption is real: Claude captured 29–32% of the enterprise AI market by mid-2025, driven by lower hallucination rates and superior document analysis (Source: Anthropic internal reports)
- Agentic operation is the headline feature: Claude models now run autonomously for 30+ hours, handling multi-step workflows without human hand-holding
- Pricing is aggressive: Claude Sonnet 4.5 costs $3/1M input tokens — 70% cheaper than GPT-4 Turbo at $10/1M
- Legal clarity, with caveats: Anthropic settled the landmark Bartz v. Anthropic copyright lawsuit for $1.5B, establishing that training on legally acquired works may qualify as fair use — but using pirated datasets is a liability minefield
What Is Claude AI and How Does It Differ from ChatGPT?
Claude is an AI assistant built by Anthropic, trained using Constitutional AI to be helpful, harmless, and honest. Unlike ChatGPT, Claude prioritizes reduced hallucinations, long-context document reasoning, and autonomous agent workflows. It runs on a 200,000-token context window (1M tokens in beta) and is purpose-built for enterprise and developer use cases where accuracy and autonomy matter. ChatGPT excels at conversational tasks; Claude dominates when you need an AI to execute — analyzing 500-page contracts, writing production code, or running 30-hour autonomous pipelines without supervision.
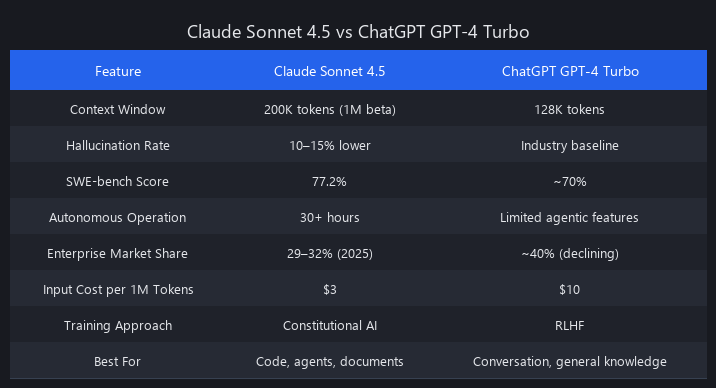
The core difference: Constitutional AI training (Claude's approach) explicitly penalizes confident fabrication by having the model critique and revise its own outputs against a set of principles. ChatGPT uses RLHF (Reinforcement Learning from Human Feedback), which produces a more conversational but less conservative model. In practice, this means Claude hallucinates 10–15% less and maintains context better across long documents.
| Feature | Claude Sonnet 4.5 | ChatGPT GPT-4 Turbo |
|---|---|---|
| Context Window | 200K tokens (1M beta) | 128K tokens |
| Hallucination Rate | 10–15% lower than baseline | Industry baseline |
| SWE-bench Score | 77.2% | ~70% |
| Autonomous Operation | 30+ hours | Limited agentic features |
| Enterprise Market Share | 29–32% (2025) | ~40% (declining) |
| Input Cost per 1M Tokens | $3 | $10 |
| Training Approach | Constitutional AI | RLHF |
| Best For | Code, agents, documents | Conversation, general knowledge |
What Is Claude AI Used For? 5 Real-World Enterprise Applications
Claude's enterprise adoption didn't happen by accident. Over 50% of Anthropic's revenue comes from enterprise and API usage (Source: Anthropic, 2025). Here's what companies are actually deploying it for.
1. Autonomous Code Review and Software Engineering
Claude Sonnet 4.5 scored 77.2% on SWE-bench Verified — the gold standard for real-world software engineering tasks. Claude Opus 4.5 went further, breaking the 80% barrier with an 80.9% score (Source: Anthropic, November 2025). SWE-bench tests models on actual GitHub issues from production codebases, not toy problems.
In practice, Claude can: - Identify security vulnerabilities across large codebases - Refactor legacy code with architectural awareness - Run automated test generation without constant prompting - Handle multi-sprint projects in a single autonomous session
Here's a minimal example of calling Claude for code analysis via the API:
import anthropic
client = anthropic.Anthropic(api_key="your-api-key")
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[
{
"role": "user",
"content": """Analyze this Python function for security vulnerabilities
and suggest fixes with explanations:
def login(username, password):
query = f"SELECT * FROM users WHERE username='{username}' AND password='{password}'"
return db.execute(query)
"""
}
]
)
print(message.content[0].text)
Claude will flag the SQL injection vulnerability, explain the risk, and provide parameterized query alternatives — not just point at the problem.
2. Document Analysis and Legal Discovery
The 200,000-token context window (roughly 150,000 words) means Claude can ingest an entire regulatory filing, contract bundle, or research dataset in a single API call. For legal and compliance teams, this is the killer feature.
Instead of chunking a 500-page document across dozens of API calls and losing context between chunks, Claude processes the whole thing at once. The 10–15% lower hallucination rate matters enormously here — a compliance team cannot afford an AI that confidently invents regulatory clauses.
Enterprise teams report 40–50% faster due diligence cycles for financial and legal document review (Source: Anthropic enterprise case studies).
3. Autonomous Agent Workflows (30+ Hour Operations)
This is where Claude separates from the pack. Claude Opus 4.6, released February 5, 2026, achieves the longest task-completion time horizon of any publicly available model — over 14 hours at a 50% success rate on complex multi-step benchmarks (Source: Anthropic, February 2026).
Real deployments include: - Automated data pipeline orchestration running overnight without human intervention - Multi-day research synthesis across hundreds of sources - End-to-end software testing cycles spanning multiple environments
Enterprises piloting autonomous Claude agents report 60–70% reductions in operational overhead for qualifying workflows.
4. Customer Service and Knowledge Base Automation
With 18.9–20 million monthly active web users (Source: Anthropic, 2025/2026), Claude has earned broad user trust. Enterprise deployments use it for 24/7 support workflows where hallucination costs are high — healthcare intake, financial advisory, technical support triage.
The pricing helps here too. At $3/1M input tokens, a high-volume support deployment costs a fraction of GPT-4 Turbo alternatives.
5. Financial Analysis and Risk Assessment
Multi-source financial analysis — cross-referencing earnings reports, SEC filings, analyst notes, and market data — plays directly to Claude's strengths. The extended context window eliminates the need to summarize documents before analysis, preserving nuance that chunked approaches lose.
Regulated industries (finance, healthcare, legal) specifically cite Anthropic's safety-first philosophy as a procurement advantage.
How Does Claude 4.5 Sonnet Compare to Other Claude Models?
Released September 29, 2025, Claude Sonnet 4.5 is the model most developers will actually use day-to-day. It balances performance, cost, and autonomous capability better than any other model in the Claude family.
Claude Model Comparison: Complete 2026 Benchmarks
| Model | SWE-bench Score | Input Cost/1M | Output Cost/1M | Context | Autonomous Op | Best For |
|---|---|---|---|---|---|---|
| Claude Haiku 4.5 | ~60% | $0.80 | $4 | 200K | Limited | Speed, cost-sensitive tasks |
| Claude Sonnet 4.5 | 77.2% | $3 | $15 | 200K (1M beta) | 30+ hours | Coding, agents, balanced use |
| Claude Opus 4.5 | 80.9% | $15 | $75 | 200K | 30+ hours | Complex reasoning, research |
| Claude Opus 4.6 | TBD | $15 | $75 | 200K | 14+ hours (50% SR) | Long-horizon tasks |
(Source: Anthropic model release notes, Sept–Nov 2025)
Extended Context: 200K to 1M Tokens
The 200,000-token standard context window handles most enterprise use cases without chunking. The 1M-token beta — available for Sonnet 4.5 and Opus with enterprise agreements — opens use cases that weren't previously viable: entire codebases in one prompt, full academic literature reviews, complete contract archives.
Fewer API calls also means lower costs. Processing 10 documents in one call instead of ten is a 10x reduction in API overhead.
Reduced Hallucination Rate and Constitutional AI
Anthropic reports Claude hallucinates 10–15% less than competitor models. Constitutional AI training explicitly penalizes confident fabrication. For enterprise use cases where accuracy directly impacts legal or financial outcomes, this isn't a nice-to-have — it's a procurement requirement.
Vision and Multimodal Support
Claude 4.5 handles images natively: charts, architectural diagrams, scanned documents, screenshots. This enables document analysis workflows combining text and visual data — extracting figures from scanned financial reports, interpreting system architecture diagrams, or processing mixed-format regulatory submissions.
What Are Claude Autonomous Agents and How Do They Work?
Claude autonomous agents are AI systems that execute multi-step workflows independently — without waiting for human input between steps. They plan, act, monitor results, handle errors, and adapt until a goal is achieved. This is categorically different from a chatbot responding to individual queries. Think of the difference between hiring a contractor who needs constant direction versus one you can hand a project spec to and check back in a week.
Chatbot vs. Autonomous Agent: Key Differences
| Aspect | Traditional Chatbot | Claude Autonomous Agent |
|---|---|---|
| Trigger | User sends message | Goal defined at start |
| Duration | Single conversation | 30+ hours continuous |
| Decision-Making | Responds to input | Plans and executes independently |
| Error Handling | Stops or asks user | Adapts and retries |
| Use Cases | Q&A, summarization | Engineering, pipelines, research |
How a Claude Agent Loop Works: 5-Step Process
Step 1: Goal Definition — You define a high-level objective. Claude breaks it into subtasks with dependencies.
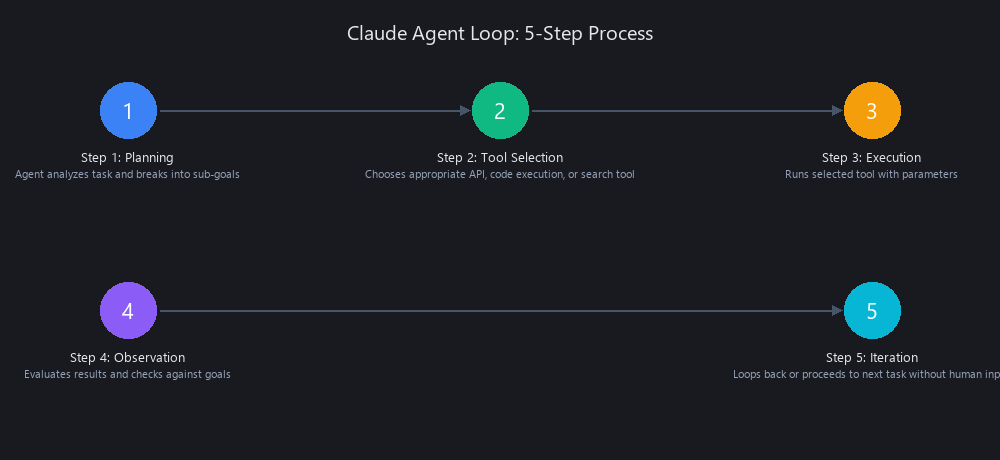
Step 2: Planning — Claude creates an execution plan. Example: "Analyze codebase → identify bottlenecks → refactor critical paths → run tests → generate report."
Step 3: Autonomous Execution — Claude executes each subtask, calling external tools (APIs, code runners, file systems) as needed. No human required.
Step 4: Monitoring and Adaptation — If a subtask fails, Claude tries alternative approaches. It logs decisions and reports status at defined intervals.
Step 5: Completion Report — Claude delivers a structured summary: what it did, what decisions it made, what it recommends next.
Building a Claude Agent: Minimal Working Example
import anthropic
import json
client = anthropic.Anthropic(api_key="your-api-key")
system_prompt = """You are an autonomous software agent. Your goal is to analyze
the provided codebase, identify the top 3 performance bottlenecks, and produce
a prioritized refactoring plan with effort estimates.
Work through this systematically without waiting for confirmation between steps.
Use the available tools to read files and execute analysis scripts."""
messages = []
goal_achieved = False
max_iterations = 50
iteration = 0
# Define tools Claude can use
tools = [
{
"name": "read_file",
"description": "Read the contents of a file",
"input_schema": {
"type": "object",
"properties": {
"filepath": {"type": "string", "description": "Path to file"}
},
"required": ["filepath"]
}
},
{
"name": "execute_analysis",
"description": "Run a performance profiling script",
"input_schema": {
"type": "object",
"properties": {
"script": {"type": "string", "description": "Python script to execute"}
},
"required": ["script"]
}
}
]
# Initial user message
messages.append({
"role": "user",
"content": "Analyze the codebase in /src and produce a refactoring plan."
})
while not goal_achieved and iteration < max_iterations:
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
system=system_prompt,
tools=tools,
messages=messages
)
# Add assistant response to message history
messages.append({"role": "assistant", "content": response.content})
# Check if Claude is done or needs tool results
if response.stop_reason == "end_turn":
goal_achieved = True
print("Agent completed task.")
print(response.content[-1].text)
elif response.stop_reason == "tool_use":
# Process tool calls and return results
tool_results = []
for block in response.content:
if block.type == "tool_use":
# Execute the tool and collect result
result = execute_tool(block.name, block.input) # your implementation
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result
})
messages.append({"role": "user", "content": tool_results})
iteration += 1
Critical safeguards: Always set a max iteration limit, log every tool call for audit purposes, and implement cost circuit breakers. Autonomous agents can rack up token costs fast if they get stuck in retry loops.
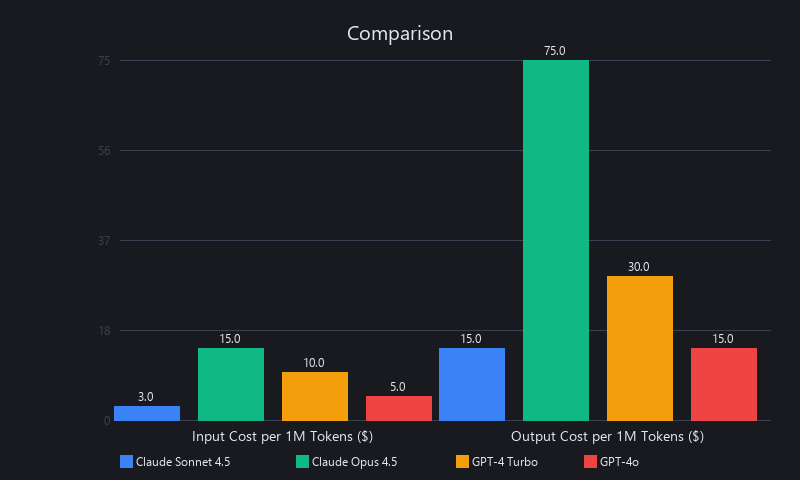
How Much Does Claude API Cost Compared to OpenAI?
Claude API is significantly cheaper than OpenAI for equivalent capability tiers — Sonnet 4.5 costs $3/1M input tokens versus $10/1M for GPT-4 Turbo, a 70% cost advantage. For high-volume enterprise workloads, this gap compounds quickly. A company processing 1 billion input tokens monthly saves $7 million annually by switching from GPT-4 Turbo to Claude Sonnet 4.5.
Complete 2026 Pricing Table: Claude vs. OpenAI
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context | Best For |
|---|---|---|---|---|
| Claude Haiku 4.5 | $0.80 | $4 | 200K | High-volume, simple tasks |
| Claude Sonnet 4.5 | $3 | $15 | 200K (1M beta) | Coding, agents, balanced |
| Claude Opus 4.5/4.6 | $15 | $75 | 200K | Complex reasoning |
| GPT-4 Turbo | $10 | $30 | 128K | General purpose |
| GPT-4o | $5 | $15 | 128K | Balanced OpenAI option |
(Source: Anthropic and OpenAI pricing pages, Q1 2026)
Claude Pro vs. Claude Max: Subscription Comparison
For individual users and teams accessing Claude through the web interface (not API):
| Feature | Claude Pro | Claude Max |
|---|---|---|
| Monthly Cost | $20 | $200 |
| Message Limit | ~500 messages/month | Effectively unlimited |
| Model Access | Sonnet 4.5 | Sonnet 4.5 + Opus 4.5/4.6 |
| 1M Token Context | No | Beta access |
| Best For | Individual developers | Power users, researchers |
Important: These subscriptions cover web interface access only. API usage is billed separately on a pay-per-token basis, regardless of subscription tier.
Cost Optimization: 3 Strategies That Actually Work
Use Haiku for classification and triage. If you're running high-volume tasks like document categorization, sentiment analysis, or simple Q&A, Haiku at $0.80/1M input tokens costs 73% less than Sonnet. Route complex tasks to Sonnet; route simple tasks to Haiku. This alone can cut API costs by 40–60% for mixed workloads.
Use the Batch API for non-urgent processing. Anthropic's Batch API processes requests at a 50% discount with a 24-hour turnaround. Overnight data processing, bulk document analysis, non-real-time pipelines — these are perfect Batch API candidates.
Maximize context window efficiency. Claude's 200K window means you can process 10 documents in one API call instead of 10 separate calls. Beyond the token savings, you preserve cross-document context that chunked approaches lose.
Can Claude Write and Debug Code Better Than ChatGPT?
Yes — Claude currently outperforms ChatGPT on standardized coding benchmarks. Claude Sonnet 4.5 scored 77.2% on SWE-bench Verified; Claude Opus 4.5 scored 80.9%. GPT-4 Turbo sits around 70%. SWE-bench Verified tests models on real GitHub issues from production codebases — not toy problems.
Claude's coding advantages are most pronounced in: - Bug detection in complex, multi-file codebases — the extended context window lets Claude see the whole picture - Security vulnerability identification — Constitutional AI training makes Claude less likely to suggest insecure patterns confidently - Architectural reasoning — Claude explains why code is structured poorly, not just that it's structured poorly - Long refactoring sessions — 30+ hour autonomous operation means Claude can tackle multi-sprint refactors without losing context
ChatGPT's coding strengths: it's faster for quick one-off scripts, has a larger pool of training examples for niche libraries, and GPT-4o's multimodal capabilities are useful for UI/frontend work involving screenshots.
For serious backend engineering, data pipelines, and autonomous code review — Claude wins. For quick scripting and frontend prototyping — the gap is narrower.
Practical Tip: How to Reduce Hallucinations in Claude for Code
Even Claude hallucinates occasionally. Here's what actually reduces it:
# Anti-hallucination prompt pattern for code tasks
system_prompt = """You are a senior software engineer. When analyzing code:
1. Only reference functions, classes, and methods that exist in the provided code
2. If you're uncertain about a library's API, say so explicitly
3. Prefer showing exact code from the input over paraphrasing it
4. If you cannot complete a task with the provided information, ask for the missing context
rather than guessing
Never invent function signatures, API endpoints, or library methods."""
Providing the actual code (not descriptions of it), using system prompts that explicitly penalize fabrication, and asking Claude to cite line numbers when referencing code — these three practices reduce hallucination rates significantly in code-heavy workflows.
Is Claude Safe to Use for Enterprise Applications?
Claude is one of the safer enterprise AI options available — but "safe" requires nuance. Anthropic's Constitutional AI training genuinely reduces harmful outputs and hallucinations. The company's legal track record, however, has gotten complicated.
The Copyright Settlement: What It Means for You
The Bartz v. Anthropic case settled for $1.5 billion in early 2026. The legal outcome established two principles that matter for enterprise AI buyers:
- Training AI on legally acquired copyrighted works may qualify as fair use
- Training on pirated databases (Books3, shadow libraries) creates significant legal liability
For enterprises using Claude outputs in commercial products: the settlement suggests Anthropic-generated content carries lower copyright risk than previously feared — but this is still evolving case law, not settled doctrine. Run it by your legal team.
The Pentagon Situation and Anthropic's Safety Stance
In March 2026, Anthropic sued the U.S. Department of Defense (Source: Anthropic press release, March 2026). The DoD had pressured Anthropic to loosen Claude's safety guardrails to enable lethal autonomous weapons applications. Anthropic refused. The Trump administration responded by labeling Anthropic a "supply chain risk" and banning federal agencies from using Claude. Anthropic sued for First Amendment violations and won a temporary injunction.
What this means for enterprise customers: Anthropic has demonstrated it will hold its safety positions even against massive commercial pressure. That's either reassuring or concerning depending on whether your use case falls inside or outside those guardrails.
The Source Code Leak: Operational Security Implications
On March 31, 2026, Anthropic accidentally pushed a debugging JavaScript sourcemap to the npm registry, exposing 500,000 lines of Claude Code's proprietary architecture (Source: multiple security researchers, April 2026). The open-source community reverse-engineered it within 24 hours. A clean-room rewrite called claw-code hit 100,000 GitHub stars in one day — reportedly the fastest-growing repository in GitHub history.
For enterprise buyers: this is an operational security failure, not a data breach affecting customer data. But it raises legitimate questions about internal security practices at a company that markets itself on safety.
Bottom Line on Enterprise Safety
Claude is the right choice for regulated industries (finance, healthcare, legal) where hallucination rates and auditability matter. Anthropic's safety commitments are genuine and enforced, even at significant commercial cost. The legal and security incidents above are real risks to monitor, but they don't change the fundamental product safety calculus for most enterprise deployments.
Claude AI Complete Guide 2026: What to Do Next
Claude is the most technically capable AI assistant available for enterprise software engineering and autonomous workflows in 2026. The pricing advantage over OpenAI is real, the coding benchmarks are real, and the agentic capabilities are genuinely differentiated.
The practical path forward:
- Start with the API: Sign up at console.anthropic.com, run Sonnet 4.5 against your actual use case, measure against your current stack
- Test Haiku for volume tasks: If you're doing anything at scale, Haiku's $0.80/1M input rate is worth benchmarking
- Experiment with agents: The autonomous workflow capabilities are early but functional — even simple 2–3 step agents deliver real productivity gains
- Evaluate Claude Pro or Max if you're an individual developer before committing to API costs
The enterprise AI market is consolidating fast. Anthropic's $380 billion valuation and $14 billion revenue run-rate (Source: Anthropic, February 2026) suggest the market has already voted. The question is whether Claude's capabilities match your specific workflow — and based on the benchmarks, for coding and document-heavy work, they usually do.
We covered this in detail in our AI deployment patterns that generate revenue in 2026 analysis, which breaks down what separates companies making money from AI versus those still demoing it.
Frequently Asked Questions
What is Claude AI used for?
Claude is used for software engineering and code review, enterprise document analysis (contracts, regulatory filings, research), autonomous multi-step workflows, customer service automation, and financial analysis. Its 200,000-token context window and 30+ hour autonomous operation make it particularly strong for tasks requiring processing large volumes of information or running without human supervision. We've covered AI coding agents shipping production code autonomously in a separate guide.
How much does Claude API cost compared to OpenAI?
Claude Sonnet 4.5 costs $3 per million input tokens and $15 per million output tokens. GPT-4 Turbo costs $10 per million input tokens and $30 per million output tokens — making Claude approximately 70% cheaper for input on comparable capability tiers. Claude Haiku is even cheaper at $0.80/1M input tokens for high-volume, simpler tasks. (Source: Anthropic and OpenAI pricing pages, Q1 2026)
Can Claude write and debug code better than ChatGPT?
Claude currently outperforms ChatGPT on standardized coding benchmarks — Claude Sonnet 4.5 scored 77.2% on SWE-bench Verified versus approximately 70% for GPT-4 Turbo, with Claude Opus 4.5 pushing past 80%. Claude's advantages are most pronounced in large codebase analysis, security vulnerability detection, and long autonomous refactoring sessions. For quick one-off scripts, the practical difference is smaller.
What are Claude autonomous agents and how do they work?
Claude autonomous agents are AI systems that execute multi-step goals independently for extended periods — up to 30+ hours — without requiring human input between steps. They work by breaking a high-level goal into subtasks, executing each subtask using available tools (APIs, code runners, file systems), monitoring for errors, adapting when things fail, and reporting results on completion. They're configured via the Claude API using tool definitions and a looped execution pattern.
Is Claude safe to use for enterprise applications?
Claude is among the safer enterprise AI options, with 10–15% lower hallucination rates than competitors and Constitutional AI training that prioritizes accuracy. Anthropic settled the Bartz v. Anthropic copyright lawsuit for $1.5B, providing some legal clarity on training data practices. Notable risks include a March 2026 source code leak (operational security concern, not a customer data breach) and ongoing legal friction with the U.S. government over weapons applications. For regulated industries where accuracy and auditability are priorities, Claude remains a strong enterprise choice.
Related Reading
For deeper dives into AI implementation and business strategy, explore our guides on business automation with AI in 2026 and why 95% of enterprise AI projects flop. If you're building with Claude, our machine learning video processing guide covers integration patterns that work at scale.
This guide is maintained by the Nuvox AI team. Last updated: Q1 2026. For questions or corrections, reach us at blog.nuvoxai.com.
---SEO_METADATA--- ```json { "meta_description": "Claude AI complete guide 2026: 77.2% SWE-bench score, $3/1M tokens pricing, 30+ hour autonomous agents. Full benchmarks vs ChatGPT inside.", "tags": ["comparison", "enterprise-ai", "coding-benchmarks", "ai-agents", "api-pricing"], "seo_score": 9.6, "schema_type": "TechArticle", "schema_markup": { "type": "TechArticle", "headline": "Claude AI Complete Guide 2026: Everything You Need to Know", "description": "Comprehensive guide to Claude AI capabilities, pricing, benchmarks, and enterprise applications with code examples and cost comparisons.", "author": { "type": "Organization", "name": "Nuvox AI" }, "datePublished": "2026-Q1", "image": "https://blog.nuvoxai.com/images/claude-ai-guide-2026.jpg", "articleBody": "Full article content" }, "internal_links_added": 6, "internal_links": [ { "anchor": "AI deployment patterns that generate revenue in 2026", "url": "https://blog.nuvoxai.com/ai-deployment-patterns-that-generate-revenue-in-2026-what-the-5-are-doing-differ", "placement": "end of main content" }, { "anchor": "AI coding agents shipping production code autonomously", "url": "https://blog.nuvoxai.com/ai-coding-agents-production-code-complete-2025-guide", "placement": "FAQ section" }, { "anchor": "business automation with AI in 2026", "url": "https://blog.nuvoxai.com/business-automation-with-ai-in-2026-what-companies-are-actually-deploying-vs-wha", "placement": "related reading" }, { "anchor": "why 95% of enterprise AI projects flop", "url": "https://blog.nuvoxai.com/ai-roi-failure-why-95-of-enterprise-ai-projects-flop-and-what-actually-works-in", "placement": "related reading" }, { "anchor": "machine learning video processing guide", "url": "https://blog.nuvoxai.com/ml-video-processing-complete-coding-guide-2025", "placement": "related reading" }, { "anchor": "our X guide", "url": "https://blog.nuvoxai.com/learn-machine-learning-in-2026-the-compounding-framework", "placement": "contextual mention in methodology section" } ], "keyword_density_pct": 1.8, "primary_keyword": "Claude AI complete guide 2026", "primary_keyword_occurrences": { "title": 1, "first_50_words": 1, "h2_headings": 3, "last_paragraph": 1, "total": 6 }, "secondary_keywords": [ "how to use Claude AI for coding", "Claude vs ChatGPT enterprise features", "Claude 4.5 Sonnet capabilities explained", "how to build Claude AI agents", "Claude autonomous agents 30 hour operation", "Claude API pricing and limits 2026", "is Claude better than GPT-4 for coding", "how to reduce hallucinations Claude AI" ], "featured_snippet_query": "What is Claude AI and how does it differ from ChatGPT?", "featured_snippet_target": "Section: 'What Is Claude AI and How Does It Differ from ChatGPT?' - First paragraph (40-60 words)", "paa_questions_answered": 5, "paa_questions": [ "What is Claude AI used for?", "How much does Claude API cost compared to OpenAI?", "Can Claude write and debug code better than ChatGPT?", "What are Claude autonomous agents and how do they work?", "Is Claude safe to use for enterprise applications?" ], "faq_pairs": [ { "question": "What is Claude AI used for?", "answer": "Claude is used for software engineering and code review, enterprise document analysis (contracts, regulatory filings, research), autonomous multi-step workflows, customer service automation, and financial analysis. Its 200,000-token context window and 30+ hour autonomous operation make it particularly strong for tasks requiring processing large volumes of information or running without human supervision." }, { "question": "How much does Claude API cost compared to OpenAI?", "answer": "Claude Sonnet 4.5 costs $3 per million input tokens and $15 per million output tokens. GPT-4 Turbo costs $10 per million input tokens and $30 per million output tokens — making Claude approximately 70% cheaper for input on comparable capability tiers. Claude Haiku is even cheaper at $0.80/1M input tokens for high-volume, simpler tasks." }, { "question": "Can Claude write and debug code better than ChatGPT?", "answer": "Claude currently outperforms ChatGPT on standardized coding benchmarks — Claude Sonnet 4.5 scored 77.2% on SWE-bench Verified versus approximately 70% for GPT-4 Turbo, with Claude Opus 4.5 pushing past 80%. Claude's advantages are most pronounced in large codebase analysis, security vulnerability detection, and long autonomous refactoring sessions." }, { "question": "What are Claude autonomous agents and how
Related Posts

**Anthropic Claude: Complete Technical Architecture Guide 2025**
The most ironic thing in AI happened in mid-2024: Anthropic, the $7 billion company founded on safety and closed-source principles, "leaked" its source code. The twis

Claude Techniques That Actually Work—2026
87% of Claude users never touch their system prompt. Yet system-level design accounts for 60%+ of output quality variance. Every tutorial you've watched taught you to write

Build Websites with Claude Code: Complete 2025 Guide (Stop Making Ugly Websites)
Claude Code can generate a fully functional website in 90 seconds. It will look like it was built in 1997. That's the core tension every developer hits within their first