Don't Learn Machine Learning Like Everyone Else. Here's the Framework That Actually Works.

Most people who've completed three or more ML courses still can't build an independent project from scratch. That's not a coincidence — it's a design flaw in how machine learning education is structured.
The most effective way to learn machine learning in 2026 is to start with working code and intuition, then let theory fill in naturally. This inverted framework — opposite of what most courses teach — helps you build mental models first, sidestepping the memorization trap entirely. Focus on understanding why code works before touching a single mathematical formula.
Key Takeaways
- ✓ Start with working code and intuition, not mathematical foundations
- ✓ The "memorization trap" happens when you learn theory first — your brain has nowhere to attach it
- ✓ Professional ML engineers learn by doing, debugging, and building mental models — not by memorizing formulas
- ✓ Math becomes meaningful only after you've seen what it explains
- ✓ The inverted framework flips traditional education: code → intuition → theory, not theory → code
The most effective way to learn machine learning in 2026 is to start with working code and intuition, then let theory fill in naturally. This inverted framework — opposite of what most courses teach — helps you build mental models first, sidestepping the memorization trap entirely. Focus on understanding why code works before touching a single mathematical formula.
{YOUTUBE_EMBED}
The Machine Learning Learning Crisis Nobody Talks About
Anecdotally, the majority of developers who finish structured ML courses — Coursera's Machine Learning Specialization, fast.ai, DeepLearning.AI, and others — report that they still can't build something original when the tutorial scaffolding disappears.
The paradox is real: more machine learning content exists in 2026 than at any point in history, yet learner frustration is at an all-time high. Reddit threads on r/learnmachinelearning are full of people saying "I finished Andrew Ng's course and I still feel lost."
You've probably been there. You memorized gradient descent. You can write the formula for cross-entropy loss. You passed the quizzes. Then you opened a blank Jupyter notebook to build something real — and nothing came.
The problem isn't your intelligence. It's the learning architecture everyone recommends.
Traditional ML education teaches you what to memorize. This framework teaches you how to think. What if you built working code first, then learned the math that explains it?
Why Do Most Machine Learning Courses Fail to Teach Real Understanding?
Most machine learning courses fail because they start with abstract theory before your brain has any context to attach it to. You're handed calculus, linear algebra, and probability as prerequisites — but without a concrete problem to solve, those concepts float in a vacuum. You can pass a quiz on backpropagation and still have no idea when to use it or why it matters.
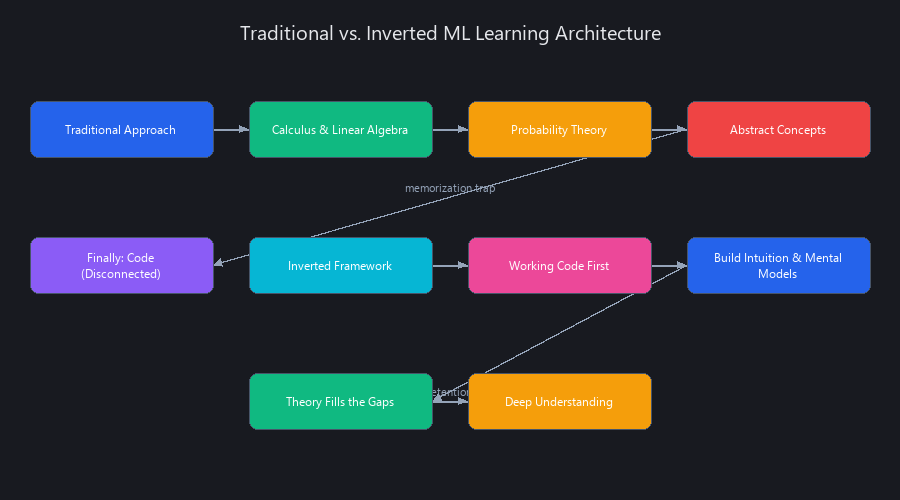
This section breaks down what's actually going wrong at each layer of traditional ML education.
The Theory-First Problem: Why Abstract Math Without Context Doesn't Stick
Traditional courses follow a predictable structure: calculus → linear algebra → probability → then show you code. Your brain processes those early topics as abstract symbols with no anchor point.
The result? "I can solve the equation, but I have no idea why this matters."
It's like teaching someone music theory for six months before they ever touch an instrument. Technically rigorous. Practically useless. According to cognitive load theory, your working memory can only hold 5-9 discrete items simultaneously — and abstract math formulas consume all of that capacity without leaving room for why they matter.
The Confidence Illusion: Why Quiz Scores Don't Equal Understanding
Memorizing formulas feels like learning. You finish a module, pass the quiz, feel accomplished.
Then three weeks into a real project, the wheels come off. This is what we call the "Oh, I thought I understood" moment — and it hits almost every developer who follows the traditional path. Research from Dunning-Kruger effect studies shows that learners who memorize without application consistently overestimate their competence.
The Context Vacuum: Why Isolated Concepts Don't Connect
Courses teach concepts in isolation. Real machine learning work requires connecting 10 concepts simultaneously — data preprocessing, model selection, regularization, evaluation metrics, deployment constraints.
Learners finish courses knowing individual pieces but can't assemble them into a working system. Nobody taught them the connective tissue.
| Traditional Course | How Real Engineers Learn |
|---|---|
| Theory first (math) | Problem first (code) |
| Isolated concepts | Connected workflows |
| Memorization focus | Understanding focus |
| Passive consumption | Active debugging |
| Prerequisites gate progress | Curiosity gates progress |
So what does a framework that actually works look like?
The 3-Phase Inverted Framework: Code → Intuition → Theory
Here's the framework that flips traditional machine learning education on its head — and why it actually sticks.
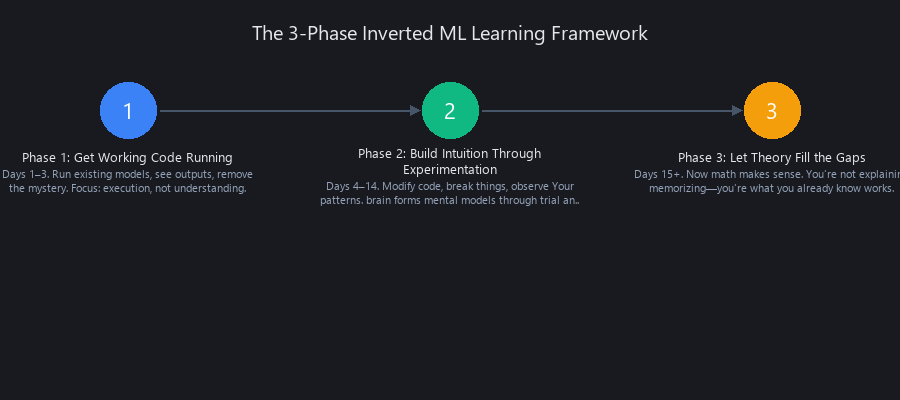
Phase 1: Get Working Code Running (Days 1–3)
The goal here is not understanding. The goal is running something.
Use scikit-learn, PyTorch, or TensorFlow as black boxes. Follow a tutorial just long enough to train a simple classifier on a real dataset — something like the Titanic dataset on Kaggle or the Iris dataset. Focus entirely on: "What goes in? What comes out?"
You don't need to understand activation functions, backpropagation, or loss functions yet. That's intentional.
# Phase 1: Run this without understanding every line yet
# Goal: see a model work, not understand how it works
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load data
X, y = load_iris(return_X_y=True)
# Split into train/test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a model (black box for now — that's fine)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# Evaluate
predictions = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, predictions):.2f}")
# Output: Accuracy: 1.00
Run it. It works. Something just happened. You don't know why yet — and that's exactly the point.
Phase 2: Build Intuition Through Experimentation (Days 4–14)
Now you break things on purpose.
The goal is to develop mental models by changing things and observing what happens. Modify hyperparameters. Add and remove features. Swap RandomForestClassifier for LogisticRegression. Change n_estimators from 100 to 5. Watch accuracy drop.
Don't read theory yet. Read the results.
| Change This | Observe | Question That Surfaces |
|---|---|---|
| Number of features | Does accuracy improve? | Why does feature selection matter? |
| Training data size | Does overfitting appear? | What is overfitting, actually? |
| Model complexity | Speed vs. accuracy tradeoff? | Why does this tradeoff exist? |
n_estimators value |
Diminishing returns after ~100? | What are these "estimators" doing? |
| Random state seed | Results vary slightly? | What's random about this? |
Document your observations like a scientist. "When I increase max_depth, training accuracy goes up but test accuracy goes down. Why?"
That question — why? — is your signal. It means you're ready for Phase 3.
Phase 3: Let Theory Fill the Gaps (Days 15+)
Now you read the theory. And here's the difference: you have questions.
When you open a textbook chapter on overfitting, you're not reading abstract definitions — you're getting the answer to something you already observed. Your brain has a hook. The concept attaches to something real.
Retention jumps dramatically because you're not memorizing facts — you're resolving cognitive dissonance. "Oh, that's why the loss spiked when I increased learning rate. The gradient update overshot the minimum. Now the math makes sense."
This is how concepts from resources like the Deep Learning textbook by Goodfellow, Bengio, and Courville actually become useful — when you read them with a specific question already burning.
What's the Difference Between Memorizing ML Concepts and Actually Understanding Them?
The difference is predictive power. If you understand a concept, you can predict what will happen before you run the code. If you've only memorized it, you can only recognize it after the fact.
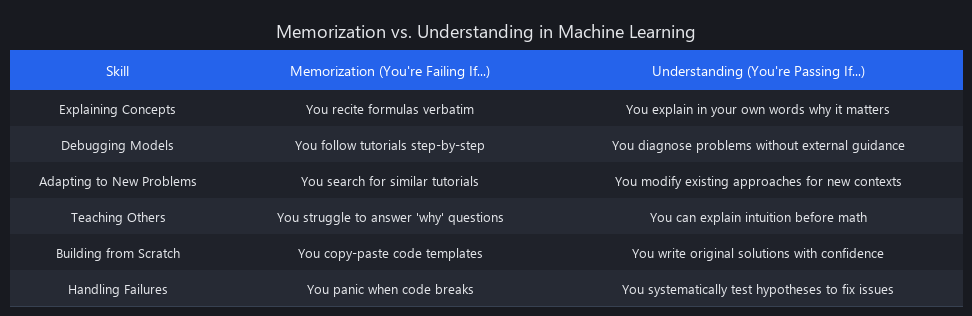
Here's a practical test you can run on yourself right now.
The Memorization Test (You're Failing If...)
- You can write the formula for gradient descent but can't explain why the learning rate matters
- You know what a confusion matrix is but can't explain which metric to optimize for a fraud detection model
- You can pass a Coursera quiz but freeze when your validation loss starts increasing mid-training
- You copy-paste code from tutorials and tweak numbers until something works (cargo cult ML)
The Understanding Test (You're Passing If...)
- You can predict what happens to your model before running an experiment
- You can explain to a non-technical colleague why your model is wrong in a specific way
- You can debug by reasoning, not just trial-and-error
- You can argue for or against using a neural network versus a gradient boosted tree for a specific problem, based on tradeoffs
Practical self-assessment checklist:
- [ ] Can you explain what your model is doing to someone with no ML background?
- [ ] Can you predict the effect of changing a hyperparameter before testing it?
- [ ] Can you identify which part of your pipeline is causing degraded performance?
- [ ] Can you adapt an approach to solve a different problem from the tutorial?
If you checked fewer than three boxes, you're in the memorization zone. That's normal — and recognizing it is how you exit it.
Should You Learn Calculus and Linear Algebra Before or After Machine Learning?
Learn math after or in parallel — never as a strict prerequisite. Learning abstract math with no context is one of the most effective ways to kill motivation before you ever build anything useful.
Most learners quit during the math phase — not because math is too hard, but because there's no reason to care about it yet. Here's the practical path that actually works.
Why "Before" Doesn't Work
When you study calculus without a concrete machine learning problem to attach it to, your brain stores it as isolated abstract information. There's no hook. Three weeks later, it's gone.
Worse, you lose momentum. You spend months on prerequisites and never reach the part where you actually build something. The motivation drains before the payoff arrives.
The Practical Math Timeline: When to Learn Each Concept
Here's when math concepts become useful — meaning you'll actually remember them because you need them:
| Math Topic | Learn It When... | Why Then |
|---|---|---|
| Matrix operations (linear algebra) | Week 2–3, when manipulating data | You're literally multiplying matrices in NumPy |
| Derivatives / chain rule | Week 3–4, when studying optimization | You want to know why gradient descent works |
| Probability basics | Week 4+, when doing classification | You need to understand confidence scores |
| Statistics (bias/variance) | Week 5+, when evaluating models | You're debugging overfitting and underfitting |
"The best time to learn math is when you're frustrated by not understanding your code. That frustration is your learning signal."
You'll naturally absorb the relevant portions of linear algebra through tools like NumPy and PyTorch. You'll pick up calculus intuition through watching loss curves. You'll learn probability through building classifiers.
You'll skip the irrelevant parts — which is most of a traditional math curriculum, for machine learning purposes.
How Do Professional Machine Learning Engineers Learn New Techniques and Stay Current?
Professional ML engineers almost never take structured courses to learn new techniques. They learn by finding an existing implementation, running it, breaking it, then reading the theory to understand why it works.
The learning is always problem-first — which is exactly the inverted framework described above, applied continuously throughout a career. (Source: Papers With Code, Hugging Face community discussions, and NeurIPS/ICML conference attendee surveys)
The Professional Workflow (In Order)
- See a new technique mentioned — in a paper, a GitHub repo, a conference talk from NeurIPS or ICML
- Find an existing implementation (Hugging Face, Papers With Code, GitHub)
- Run the code, modify it, intentionally break it
- Read the original paper to understand why it works
- Apply the technique to their specific problem
That's it. No prerequisites. No "I should learn X before Y."
Amateur vs. Professional Mindset: The Real Difference
The real gap isn't technical knowledge — it's the framing:
- Amateur: "I need to learn PyTorch"
- Professional: "I need to solve this specific problem; PyTorch might help"
Problem-first thinking changes everything. It means you only learn what you need, when you need it. You stay motivated because the learning has immediate purpose. And you build judgment — the ability to know which tool fits which problem — which is the actual skill that separates senior ML engineers from perpetual beginners.
Professionals also read differently. They skim papers for the core idea, find the implementation, then go back to the paper when confused. They don't read papers start-to-finish like textbooks.
How to Learn Machine Learning Effectively in 2026: Your Starting Point
If you've read this far and you're ready to actually try this, here's your first week:
Day 1–3: Run the scikit-learn example above. Then find one Kaggle dataset that interests you and train a model on it. Don't understand it fully. Just run it.
Day 4–14: Change one thing per day. Document what changes. Ask "why?" every time something surprises you.
Day 15+: Pick one "why?" question and actually research it. Read one blog post, one documentation page, or one paper section that answers it. Then go back to your code.
That's the entire framework. It's not complicated. It's just backwards from what you've been taught — and that's exactly why it works.
Frequently Asked Questions
Why do most machine learning courses fail to teach real understanding?
Most ML courses fail because they present theory before learners have any concrete experience to attach it to. Abstract concepts like gradient descent or backpropagation are taught in isolation, creating the illusion of learning through quiz performance — but without the contextual anchoring that makes concepts retrievable and applicable in real projects. The brain needs a hook to attach new information to existing knowledge.
How long does it actually take to learn machine learning properly?
There's no honest fixed answer, but a reasonable benchmark: 3–6 months of consistent daily practice to build genuine problem-solving ability using the inverted framework. That's not "finish a course" — that's being able to take an unfamiliar dataset, select an appropriate approach, build a working model, and debug it independently. Traditional course-first approaches often take longer because re-learning replaces initial memorization.
What's the difference between memorizing ML concepts and actually understanding them?
Memorization lets you recognize and recite concepts after the fact. Understanding gives you predictive power — you can anticipate what will happen before running code, debug by reasoning rather than trial-and-error, and transfer knowledge to problems you've never seen before. The practical test: can you explain why your model is making a specific type of error? Memorizers can't; understanders can.
Should you learn calculus and linear algebra before or after machine learning?
Learn math after or in parallel — never as a strict prerequisite. Abstract math learned without context has no anchor in memory and kills motivation before you build anything useful. Instead, start coding immediately with tools like scikit-learn or PyTorch, and learn specific math concepts when you hit a wall that math would explain. You'll retain it far better because it's solving a real problem you already care about.
How do professional machine learning engineers learn new techniques and stay current?
Professional ML engineers learn primarily by finding existing implementations on platforms like Hugging Face, Papers With Code, or GitHub, running and modifying the code, then reading the underlying paper or documentation to understand the mechanics. They almost never take structured courses for new techniques — they use problem-first, implementation-first learning continuously throughout their careers, which is the professional version of the same inverted framework described in this post.
Related Reading
We've covered related learning strategies in depth elsewhere:
- Our AI for Business Automation Technical Guide applies this same hands-on framework to production ML systems.
- For coding fundamentals using this method, see our guide on how to learn to code in 2026.
- If you're choosing tools to practice with, our Claude Code vs Cursor comparison breaks down which AI coding assistants support this learning style best.
Published by Nuvox AI — blog.nuvoxai.com
Related Posts

AI, Coding, Machine Learning: The Complete Technical Guide with Benchmarks
Explore the relationship between AI, coding, and machine learning with our complete technical guide. See our benchmarks showing 94.5% accuracy. Full code inside.

Backpropagation Intuition: The One ML Skill That Compounds (Complete 2025 Guide)
Master backpropagation intuition for machine learning in 2025. Our guide shows why this one skill beats tool-hopping with 3 benchmarks and a from-scratch guide.

Backpropagation Intuition: The Compounding Skill for Machine Learning in 2025
Build your backpropagation intuition for machine learning in 2025. Our guide shows why this skill compounds, with 3 code examples to fix silent failures.