ML Fundamentals Framework: 5 Concepts That Make Every AI Tool Click in 2026

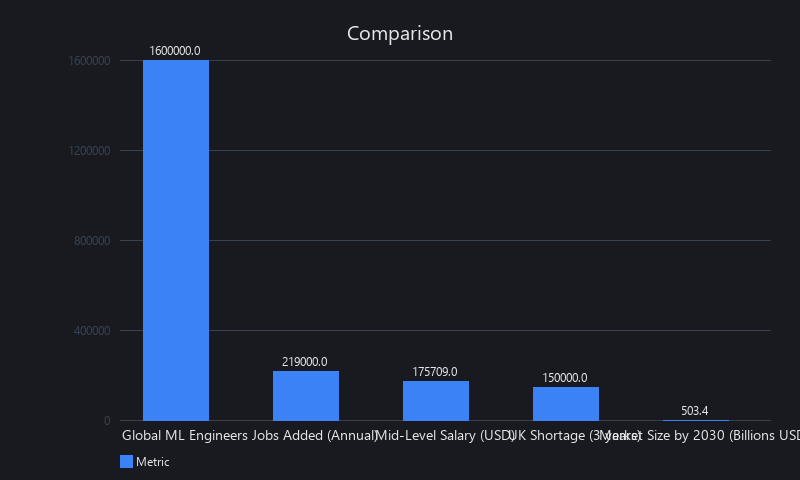
The ML job market is exploding — $503.4 billion by 2030, job postings up 89% in just the first half of 2025 — and somehow, most people learning machine learning feel more lost than ever. That's not a coincidence. That's a curriculum problem.
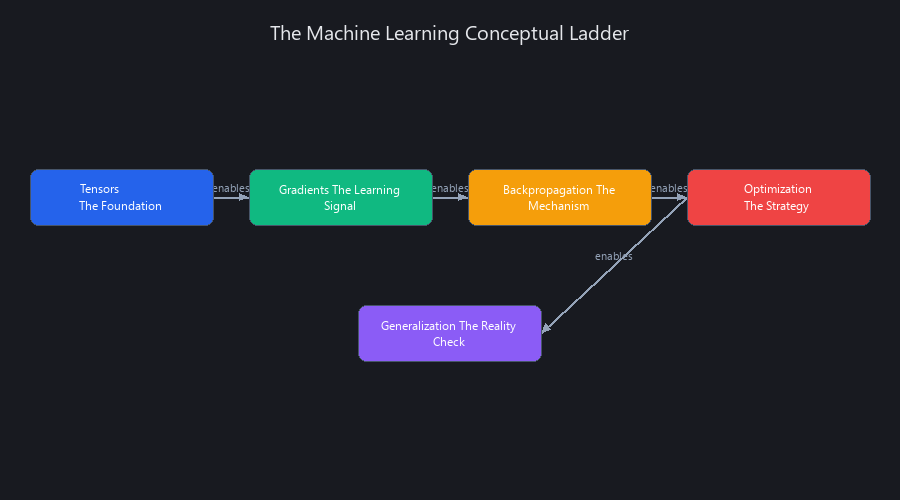
The machine learning conceptual ladder is a five-step progression — Tensors → Gradients → Backpropagation → Optimization → Generalization — where each rung depends entirely on the one below it. When you learn these concepts in order, every new model, tool, and breakthrough immediately has a place to land in your brain. Skip tensors and gradients become abstract. Miss backpropagation and optimization feels like magic. But learn them sequentially, and you'll understand GPT-4, Claude, Gemini, and whatever ships next Tuesday — because they're all built on the same five foundations.
Key Takeaways
- The conceptual ladder exists: There's a specific order to learning ML that compounds — skip rungs and you'll always feel like you're playing catch-up
- Bottom-up beats frameworks: Building from tensors and gradients up creates mental models that transfer to any new tool, any new model
- 5 concepts unlock everything: Tensors → Gradients → Backpropagation → Optimization → Generalization
- 2026 differentiator: ML engineers who understand the system underneath will outpace tool-users as AI accelerates
- Learning order beats learning volume: One hour on the right rung beats ten hours on the wrong one
What Is the Machine Learning Conceptual Ladder and Why Does Learning Order Matter?
The ML conceptual ladder is a five-step progression — Tensors → Gradients → Backpropagation → Optimization → Generalization — where each rung depends entirely on the one below it. Skip tensors and gradients become abstract. Miss backpropagation and optimization feels like magic. Learn them in sequence and every new model, every new tool, every future breakthrough immediately has a place to land in your brain.
This isn't theory. A February 2026 randomized controlled trial of 208 students at the SIGCSE Technical Symposium found that learners taught in bottom-up order scored 10% higher on conceptual understanding than those taught using library-first methods. The gap isn't talent. It's teaching sequence.
The machine learning fundamentals framework works because it mirrors how neural networks actually operate. You can't understand gradients without understanding tensors. You can't understand backpropagation without understanding gradients. You can't optimize without understanding backpropagation. And you can't build production systems without understanding generalization. Each concept is the foundation for the next.
The $503 Billion Problem: Why 89% More ML Jobs Are Opening — But Most People Still Feel Behind
The ML engineering sector currently employs roughly 1.6 million people globally and added over 219,000 jobs in a single year, according to Statista's April 2025 ML Market Report. The average mid-level ML engineer compensation in early 2025 hit $175,709. Bain & Company predicted in January 2026 that the UK alone will face a shortage of 150,000 AI professionals within three years.
So the demand is real. The money is real. The jobs are real.
And yet, learners keep reporting the same feeling: every time a new tool drops, you learn it, feel competent for about three months, then fall behind again when the next one arrives. GPT-4 to Claude to Gemini to whatever ships next Tuesday. PyTorch to JAX to something else. The treadmill never stops.
The problem isn't that you're slow. The problem is the curriculum. Most courses teach you destinations — here's how to call model.fit(), here's how to use the Hugging Face Transformers library, here's a scikit-learn pipeline. None of that is wrong. But it's teaching you addresses without teaching you how roads work.
The people who feel least behind aren't the ones who've taken the most courses. They're the ones who understand what's happening underneath. They can pick up any new framework in a weekend because they already know what the framework is doing for them. That's the compounding skill framework. And it starts with five concepts.
Why Do Most People Feel Behind in Machine Learning Education?
Most people feel behind in ML because they were taught algorithms in isolation — without the systems that execute them. A February 2026 randomized controlled trial of 208 students, presented at the SIGCSE Technical Symposium, found that students who built large language models and diffusion models from scratch scored 10% higher on conceptual understanding than those taught using library-based methods. The gap isn't talent. It's teaching order.
There's a specific trap we call the framework-first trap: learning PyTorch or TensorFlow before understanding tensors is like learning to drive an automatic transmission without knowing what an engine does. You can operate the car. You cannot fix it, modify it, or understand why it's making that noise.
The January 2026 TinyTorch curriculum — published on arXiv — proves this directly. It's a 20-module open-source course that forces students to build PyTorch's core components (tensors, autograd, optimizers) in pure Python, using only 4GB of RAM and no GPU. The result: students who go through TinyTorch understand new architectures dramatically faster than framework-first learners.
Here's what that difference looks like in practice:
| Approach | Time to First Model | Time to Understand New Tools | Resilience to Change |
|---|---|---|---|
| Framework-First | 2 weeks | 4+ weeks | Low |
| Bottom-Up | 6–8 weeks | ~1 week | High |
The bottom-up path takes longer upfront. But it's the last time you ever feel permanently behind.
How Is Bottom-Up Machine Learning Education Different from Using Frameworks?
Bottom-up ML education means you build the machinery before you use it — you implement tensors, write your own gradient calculations, and construct a training loop by hand before you ever call torch.nn. Framework-based learning skips straight to the API. It's faster to a working model, but the mental model is hollow. When something breaks or changes, bottom-up learners debug it. Framework-first learners Google it and hope.
The TinyTorch research specifically notes that students taught with off-the-shelf libraries often study gradient descent without ever measuring memory usage, or optimize a loss function without understanding what a loss function represents. That's the algorithm-systems divide — and it's why a lot of people with ML certificates still can't explain what their model is actually doing.
This is the core difference: framework users learn what to do. ML engineers learn why it works. When PyTorch releases a new version, tool users read the changelog. ML engineers read the changelog and immediately understand why each change was made. That's the difference — and it compounds over time.
The Machine Learning Fundamentals Framework for 2026: 5 Core Concepts
These five concepts build on each other. Miss one and the next one floats. Get all five in order and you have a mental model that applies to every architecture — GPT, ResNet, Stable Diffusion, whatever ships in 2027.
Concept 1: Tensors — The Foundation
A tensor is a multi-dimensional array of numbers. Scalars are 0D tensors. Vectors are 1D. Matrices are 2D. A batch of images is 3D. That's it — that's the entire data structure underlying every ML model ever built.
Why does this matter so much? Because every ML model is just tensor operations. A 28×28 MNIST image is a 2D tensor. A batch of 32 of those images is a 3D tensor with shape (32, 28, 28). A text embedding from BERT is a 2D tensor. Understanding tensors means understanding what your data actually looks like — and that mental model never expires.
import numpy as np
# 1D tensor (vector)
vector = np.array([1, 2, 3])
# 2D tensor (matrix — one grayscale image)
image = np.random.randn(28, 28)
# 3D tensor (batch of 32 images)
batch = np.random.randn(32, 28, 28)
# Element-wise operation — fast, parallel computation
scaled = batch * 0.5
print(scaled.shape) # (32, 28, 28)
Common misconception: "tensors are just fancy arrays." True — but the operations on tensors (matrix multiplication, broadcasting, reshaping) are where everything happens. Nail tensors and Concept 2 becomes obvious.
Concept 2: Gradients — The Learning Signal
A gradient is the direction and magnitude of change — it tells a model which way to adjust its weights to reduce error.
Here's the analogy: imagine you're lost in thick fog on a hillside and you need to get to the valley. You can't see anything. But you can feel the slope under your feet. The gradient is that slope — it tells you which direction is downhill. You take a step in that direction. Then recalculate. Repeat.
Every neural network — GPT-4, Llama 3, Mistral, all of them — is doing exactly this. The math underneath is just derivatives (∂Loss/∂Weight). You don't need to derive them by hand. You need to understand what they mean: change in loss per unit change in weight.
An April 2025 analysis by 365 Data Science found that niche algorithms like GANs and Graph Neural Networks appear in less than 2% of ML engineer job postings. But gradients? They're in every single model. Every time.
Concept 3: Backpropagation — The Mechanism
Backpropagation is the algorithm that efficiently calculates gradients by working backward through the network using the chain rule. Without it, training deep networks would be computationally impossible. With it, you can train GPT-3's 175 billion parameters.
The mental model: forward pass computes predictions. Backward pass computes how wrong you were, then traces that error back through every layer to every weight. It's mechanical. It's reproducible. It's not magic.
# Simplified backprop concept
def forward_pass(inputs, weights, target):
output = inputs @ weights # Matrix multiply
loss = ((output - target) ** 2).mean() # MSE loss
return output, loss
def backward_pass(inputs, output, target):
# Gradient of MSE loss with respect to output
d_output = 2 * (output - target) / len(target)
# Gradient with respect to weights (chain rule)
d_weights = inputs.T @ d_output
return d_weights
# Update step
# weights = weights - learning_rate * d_weights
Once you see that backprop is just "forward, calculate error, trace back," every architecture — Transformers, CNNs, RNNs — follows the same pattern. The architecture changes. The mechanism doesn't.
Concept 4: Optimization — The Strategy
Optimization is the algorithm that decides how much to adjust weights each step. Gradients give you the direction. Optimizers decide the step size — and bad step sizes break everything.
Take too large a step and you overshoot the minimum. Take too small a step and training takes forever (or gets stuck). This is why Adam, SGD, and RMSprop exist — they're different strategies for navigating the loss surface without flying off it.
| Optimizer | Speed | Stability | Best For |
|---|---|---|---|
| SGD | Slow | High | Learning the concept, small models |
| Momentum | Medium | Medium | General-purpose training |
| Adam | Fast | Medium | Modern deep learning (default choice) |
| AdamW | Fast | High | Large language models, Transformers |
The difference between a model that trains in 1 hour versus 10 hours is often not the architecture — it's the optimizer and learning rate schedule. Understanding optimization means understanding why AdamW became the default for LLMs and why learning rate schedules matter more than most people realize.
Concept 5: Generalization — The Reality Check
Generalization is a model's ability to perform well on new, unseen data — not just the training set it memorized.
This is the concept that makes everything else meaningful. A model that perfectly memorizes 60,000 MNIST training images and fails on the test set isn't useful. It's an expensive lookup table.
The core tension: more parameters = better training loss, worse generalization (usually). Every advanced technique in ML — dropout, batch normalization, L2 regularization, data augmentation — is really just a different answer to the same question: how do we find the signal without memorizing the noise?
Understand generalization and you immediately understand why LLMs hallucinate (they overfit to training distribution), why data augmentation works (it artificially expands the training distribution), and why cross-validation exists (it's an honest estimate of generalization).
What Skills Make You a Machine Learning Engineer vs. a Tool User?
ML engineers understand the system; tool users understand the API. When PyTorch releases a new version, tool users read the changelog. ML engineers read the changelog and immediately understand why each change was made. That's the difference — and it compounds over time.
The 365 Data Science analysis found that 57.7% of ML engineer job postings demand domain experts, not generalists. And 23.9% of postings don't require any specific degree at all. What they do require — consistently — is demonstrable systems understanding: can you explain what your model is doing, why it's failing, and how to fix it?
Tool users get stuck when the tool changes. ML engineers adapt because the underlying system hasn't changed. Tensors are still tensors. Gradients are still gradients. AlphaFold, Stable Diffusion XL, Gemini 1.5 — all different architectures, all running on the same five concepts.
This is why we've covered this in detail in our ML Skills That Compound Fastest: 2026 Guide — the compounding advantage of systems thinking compounds faster than any other skill in AI.
Can You Understand New AI Models Without Learning from Scratch?
Yes — but only if you already have the foundational mental models. If you understand tensors, gradients, backpropagation, optimization, and generalization, reading a new architecture paper takes an afternoon. Without those foundations, it takes weeks of Googling concepts you should have learned first.
DeepMind's AlphaFold database expanded to 200 million protein-structure predictions in early 2026. New transformer variants ship monthly. The specific architectures will keep changing. The five concepts won't.
When Meta released their Darwin Göodel Machine research in 2026, engineers with strong fundamentals understood the implications immediately. Those without them had to wait for tutorials. We analyzed this in depth in our Self-Improving AI 2026 guide — the frontier moves fast, but the fundamentals stay constant.
The machine learning fundamentals framework for 2026 isn't about learning everything — it's about learning the right things in the right order so that everything else becomes learnable fast.
How to Actually Start: The Bottom-Up Learning Path
If you're starting from zero, here's the sequence that works:
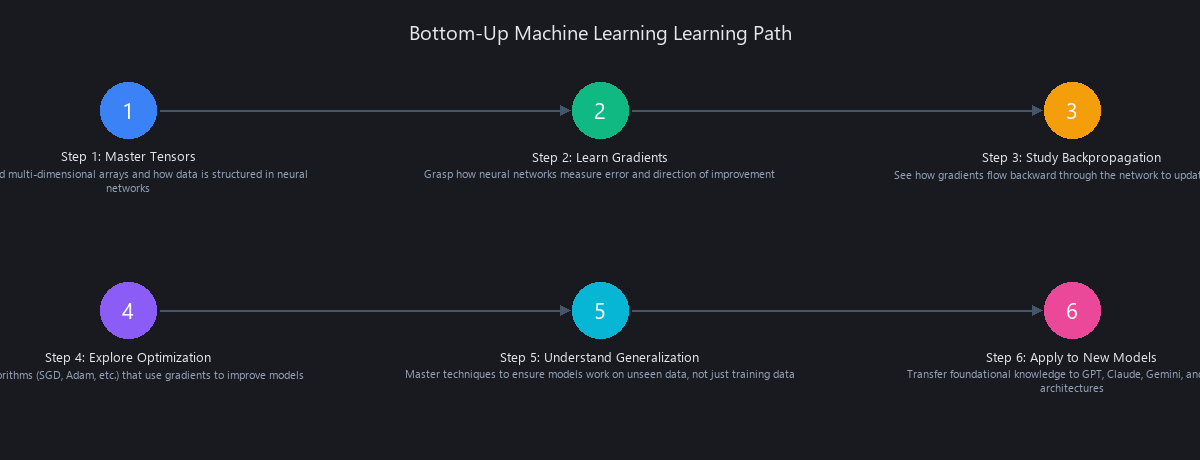
- Week 1-2: Tensors — Understand shapes, operations, broadcasting. Use NumPy, not PyTorch yet.
- Week 3-4: Gradients — Compute derivatives by hand, then with autograd. Understand ∂Loss/∂Weight.
- Week 5-6: Backpropagation — Build a simple neural network from scratch. No frameworks.
- Week 7-8: Optimization — Implement SGD, Momentum, Adam. See how step size matters.
- Week 9-10: Generalization — Train/test splits, overfitting, regularization. Understand the real problem.
- Week 11+: Frameworks — Now PyTorch and TensorFlow make sense. You're not learning syntax. You're learning shortcuts.
This path takes 10-12 weeks. Framework-first takes 2 weeks to a working model. But framework-first learners spend the next 2 years feeling behind. Bottom-up learners spend 10 weeks building a foundation that lasts a career.
Frequently Asked Questions
What are the most important machine learning concepts to learn first?
The five most important ML concepts to learn — in order — are tensors, gradients, backpropagation, optimization, and generalization. Each one depends on the previous. Start with tensors because every ML model is built on tensor operations, then work up the ladder. Skipping steps creates gaps that compound into confusion later. This sequence is why the TinyTorch curriculum works so well — it forces you through all five in order.
Why do most people feel behind in machine learning education?
Most people feel behind because they learn tools instead of systems. Courses that jump straight to scikit-learn or Hugging Face teach you API syntax, not mental models. When tools change — and they change every few months — framework-first learners have to restart. A February 2026 SIGCSE study confirmed that bottom-up learners score 10% higher on conceptual understanding than library-first learners. The curriculum order matters more than the hours spent.
How is bottom-up machine learning education different from using frameworks?
Bottom-up education means implementing the core machinery yourself — writing tensor operations, computing gradients by hand, building a training loop from scratch — before touching PyTorch or TensorFlow. Framework-based learning skips to the API. Bottom-up takes longer upfront (6–8 weeks vs. 2 weeks to a first model) but produces engineers who can debug, adapt, and understand any new tool quickly. The TinyTorch curriculum is the clearest example of this approach in 2026.
What skills make you a machine learning engineer vs. a tool user?
ML engineers understand what's happening inside the model — they can explain why a training run is diverging, what a loss curve is telling them, and how to fix a generalization problem. Tool users can call the right functions. The distinction matters: 57.7% of ML job postings in 2025 demanded domain expertise and systems understanding, not just familiarity with specific frameworks (Source: 365 Data Science, April 2025). Engineers who understand the five concepts get hired. Tool users get replaced by better tools.
Can you understand new AI models without learning from scratch?
Yes — if you have the five foundational concepts, you can understand any new model architecture quickly because every model is built on the same underlying system. Without those foundations, each new model feels like a foreign language. With them, a new architecture paper is just a new combination of familiar concepts. The foundations don't expire. The tools do. This is why we emphasized this in our Don't Learn Machine Learning Like Everyone Else guide — the framework is what compounds.
The 2026 Advantage: Why This Matters Now
The ML job market is accelerating. $503.4 billion by 2030. 89% job growth in 2025 alone. But the tools are accelerating faster than the people. GPT-4 to Claude 3.5 Sonnet to Gemini 2.0 Flash — each one a different architecture, different training approach, different capabilities.
The people who will thrive in 2026 aren't the ones who learned the most tools. They're the ones who learned the system underneath. They can read a DeepMind paper and understand it. They can debug a training run that's diverging. They can explain why batch normalization works. They can adapt to whatever ships next.
That's the machine learning fundamentals framework. That's the compounding skill. And it starts with tensors.
Sources: Statista ML Market Report (April 2025), PublicInsight Talent Data (July 2025), TinyTorch arXiv paper (January 2026), SIGCSE Technical Symposium RCT (February 2026), 365 Data Science ML Jobs Analysis (April 2025), Bain & Company AI Talent Report (January 2026), DeepMind AlphaFold Update (2026).
Related Posts

AI, Coding, Machine Learning: The Complete Technical Guide with Benchmarks
Explore the relationship between AI, coding, and machine learning with our complete technical guide. See our benchmarks showing 94.5% accuracy. Full code inside.

Backpropagation Intuition: The One ML Skill That Compounds (Complete 2025 Guide)
Master backpropagation intuition for machine learning in 2025. Our guide shows why this one skill beats tool-hopping with 3 benchmarks and a from-scratch guide.

Backpropagation Intuition: The Compounding Skill for Machine Learning in 2025
Build your backpropagation intuition for machine learning in 2025. Our guide shows why this skill compounds, with 3 code examples to fix silent failures.