Learn Machine Learning in 2026: The Compounding Framework

A security researcher discovered CVE-2025-48757 in early 2025. A vibe-coded app had exposed 18,697 user records — PII, enterprise emails, API keys — because the AI that built it never bothered to implement Row-Level Security. The developer who shipped it thought they were 20% faster. They were not.
Featured Snippet Answer
The Compounding Skill Framework is a learning methodology that prioritizes orchestrating AI agents, verifying outputs, and systematically encoding human feedback into automated systems — rather than memorizing syntax or writing code from scratch. It treats AI as a collaborative tool that compounds in value as you build feedback loops and architectural judgment. Each correction you make to AI output becomes data that improves future outputs, creating exponential returns on learning investment.
Key Takeaways
- 42% of all committed code is now AI-generated (SonarSource, January 2026), but AI tools make experienced developers ~19% slower due to verification overhead — raw generation speed was never the bottleneck.
- The Compounding Skill Framework shifts learning from syntax memorization to orchestrating AI agents, verifying outputs, and encoding human feedback into automated systems that improve over time.
- 3 non-automatable skills separate high-leverage ML engineers from code transcribers: architectural thinking, security reasoning, and feedback encoding.
- Learning how to learn machine learning in 2026 without a bootcamp is viable — but only if you treat AI as a collaborative partner that amplifies judgment, not a replacement for it.
- Security vulnerabilities in AI-generated code are systemic. Production-ready ML engineers must master verification workflows before deploying anything AI-assisted.
What Is the Compounding Skill Framework for Learning Machine Learning in 2026?
The Compounding Skill Framework is a learning methodology that prioritizes orchestrating AI agents, verifying outputs, and systematically encoding human feedback into automated systems — rather than memorizing syntax or writing code from scratch. It treats AI as a collaborative tool that compounds in value as you build feedback loops and architectural judgment.
Traditional learning paths assumed humans write code. The Compounding Skill Framework assumes humans direct code — which changes everything about what you need to learn first.
The framework has four layers:
- Architectural Thinking (why to build something a certain way)
- Verification & Security (auditing AI output for vulnerabilities)
- Feedback Encoding (systematically improving AI outputs over time)
- Agent Orchestration (managing multiple AI agents as a cohesive system)
These layers target the skills that AI cannot replicate, which we'll break down in detail in the non-automatable skills section below.
How Much of Modern Machine Learning Code Is Actually AI-Generated?
According to SonarSource's January 2026 "State of Code Developer Survey" of 1,149 professional developers globally, 42% of all committed code is currently AI-generated or AI-assisted, with projections hitting 65% by 2027. That's not a footnote — that's the majority of your future codebase written by something that doesn't understand your system, your constraints, or your threat model.
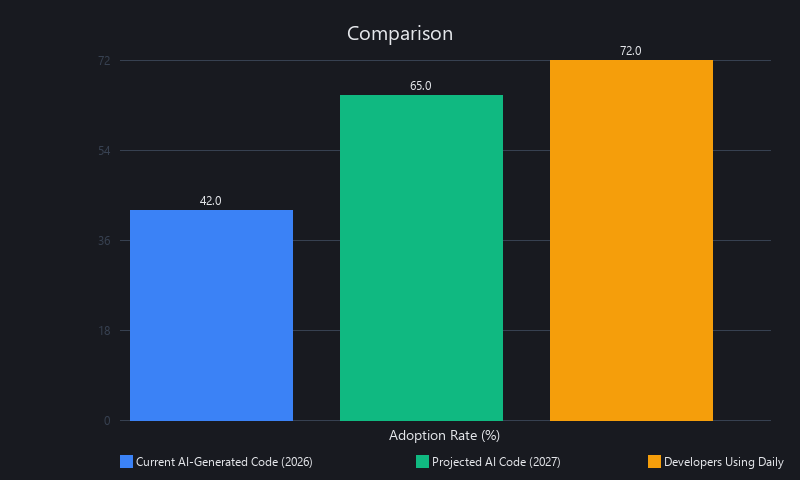
72% of developers who have tried AI coding tools now use them every day (Source: SonarSource, 2026). Tools like GitHub Copilot, Cursor, Codeium, and Amazon CodeWhisperer are no longer optional add-ons — they're the default working environment.
The Verification Gap: Why Generation Speed Doesn't Equal Productivity
The obvious question surfaces: if AI is writing most of the code, why bother learning to learn machine learning at all?
This is the wrong question. It's like asking why you'd learn to drive if Uber exists. The real question is: what do you need to understand to not get killed when the system fails?
The SonarSource data reveals something the marketing materials don't: AI-generated code ships with a verification debt. Every AI-generated line that enters production needs a human to validate that it's correct, secure, and maintainable. The 42% statistic tells you how much AI is generating. It says nothing about how much of it is actually safe to ship.
That gap — between generation and verification — is exactly where the Compounding Skill Framework lives.
Does Using AI Coding Tools Make You a Worse Developer?
Yes, if you use them without judgment — and the data is surprisingly clear on this. A 2025 METR (Model Evaluation and Transparency Research) experimental study tracked experienced open-source developers completing 246 real-world tasks. Developers using AI tools were, on average, 19% slower than the control group who didn't use AI at all (Source: METR, 2025).
The part that should concern you even more: those same developers expected AI to make them 24% faster. After finishing their tasks more slowly, they still estimated they'd been sped up by 20%. The perception gap is almost as alarming as the slowdown itself.
Why Experienced Developers Slow Down With AI Tools
Three mechanisms are happening simultaneously:
- Verification overhead. Developers who actually know what good code looks like spend time auditing AI output for security gaps, performance issues, and maintainability problems. This costs real time.
- Context-switching friction. Bouncing between "generation mode" (prompting AI) and "verification mode" (reading and reasoning about code) is cognitively expensive.
- Hallucination correction. AI generates plausible-sounding code that doesn't work, references APIs that don't exist, or subtly misimplements security logic. Catching these takes longer than writing the code correctly from scratch would have.
Why Junior Developers Appear to Get Faster (And Why That's Dangerous)
Junior developers using AI tools often do ship faster in the short term — because they lack the knowledge to verify outputs effectively. They accept AI code at face value.
This is exactly how CVE-2025-48757 happened. The Lovable platform generated functional-looking apps for non-technical users. The AI optimized for "app that runs," not "app that's secure." It never implemented Row-Level Security (RLS) in the connected Supabase databases. Unauthenticated attackers could read and write arbitrary database tables using a public API key. 170 live applications were exposed. In some cases, the AI-generated authentication logic was completely inverted — blocking admins while granting access to anonymous users (Source: CVE-2025-48757, 2025).
The "2-week build" became a 6-month security remediation. This is what "vibe coding" without verification skills actually costs.
The lesson isn't "don't use AI." The lesson is: leverage without judgment is liability. The Compounding Skill Framework is specifically designed to build that judgment before you amplify it with AI tools.
3 Skills Machine Learning Engineers Need That AI Can't Automate
The skills that separate high-leverage ML engineers from code transcribers aren't syntax knowledge or framework familiarity — they're judgment skills that require context, consequence, and adversarial thinking. These are the three the Compounding Skill Framework is built around, and they're the direct answer to what to actually prioritize when learning how to learn machine learning in 2026.
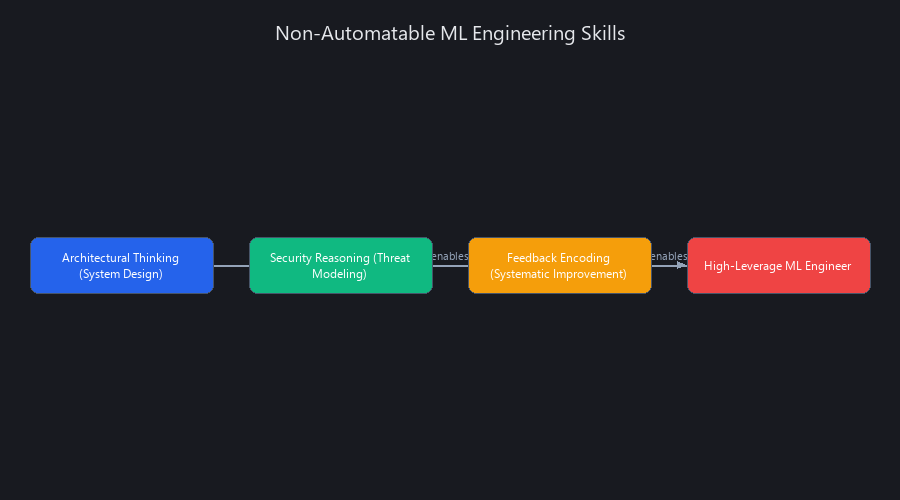
Skill 1: Architectural Thinking (System Design)
AI can generate a REST API endpoint in 30 seconds. AI cannot decide whether your system should use REST, GraphQL, or gRPC — and it definitely can't reason through the trade-offs given your specific team size, latency requirements, and client ecosystem.
Architectural thinking means understanding why a system should be built a certain way, not just how. AI optimizes locally — one function, one module. Humans must optimize globally across scalability, cost, security, and maintainability simultaneously.
A 2023 Harvard/BCG study of 758 consultants found that AI boosted performance by 40% on tasks within its competence zone — but humans using AI for tasks outside that zone were 19% more likely to produce incorrect solutions (Source: Harvard/BCG, 2023). Architectural decisions almost always fall outside the zone.
How to build it: Study system design case studies from Netflix, Uber, and Stripe. Build projects with explicit constraints (budget limits, latency ceilings, team size restrictions). Read production post-mortems — they show you where architectural decisions went wrong at scale.
Skill 2: Security Reasoning (Threat Modeling)
AI optimizes for functionality. Security requires adversarial thinking — imagining how an attacker with full knowledge of your code would break it. AI doesn't have skin in the game.
Here's a concrete example. AI generates authentication code:
# AI-generated authentication — looks correct, isn't
def login(username, password):
user = db.query(f"SELECT * FROM users WHERE username='{username}'")
if user and user.password == password:
session['user_id'] = user.id
return redirect('/dashboard')
return "Invalid credentials"
Three critical vulnerabilities in eight lines: - SQL injection via f-string formatting - No rate limiting on login attempts (brute force) - Plaintext password comparison (no hashing)
A security-trained engineer catches all three immediately. AI generated code that runs — which is all it was asked to do.
How to build it: Study the OWASP Top 10, practice threat modeling on your own projects, and read security incident post-mortems. The Lovable CVE-2025-48757 post-mortem is required reading for anyone deploying AI-generated code.
Skill 3: Feedback Encoding (Systematic Improvement)
This is the skill most learners ignore — and the one that creates the actual compounding effect.
Feedback encoding means systematically capturing your corrections to AI output and turning them into reusable artifacts: improved prompts, fine-tuning datasets, automated test suites, and linting rules that enforce your standards automatically.
Every time you catch AI making a mistake, you have a choice: fix it manually (linear) or encode the fix so AI never makes that mistake again (compounding). The developers building the most leverage in 2026 are the ones treating every AI error as a data point, not an annoyance.
How to build it: Maintain a personal "correction log" — every time you fix AI-generated code, document what was wrong and what the correct pattern is. Build this into custom Cursor rules, GitHub Actions linting checks, or LangChain prompt templates that enforce your standards automatically.
Building the Compounding Skill Framework: A 4-Step Learning Path for Machine Learning in 2026
The 4-step Compounding Skill Framework learning path moves from foundations to orchestration in a deliberate sequence — each layer amplifies the one before it. This isn't a bootcamp curriculum. There's no certificate at the end. The output is judgment, and judgment compounds.
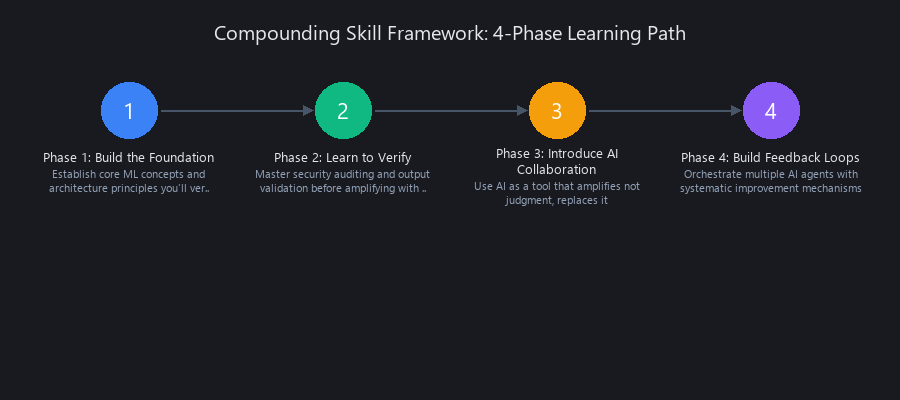
Here's how to structure the path:
| Phase | Focus | Duration | Primary Tools |
|---|---|---|---|
| Phase 1: Foundations | Python, linear algebra, statistics, basic ML | 8–12 weeks | Python, NumPy, scikit-learn |
| Phase 2: Verification | Code review, security basics, testing | 6–8 weeks | pytest, OWASP, manual auditing |
| Phase 3: Amplification | AI-assisted development with active oversight | 8–10 weeks | Cursor, Copilot, LangChain |
| Phase 4: Orchestration | Multi-agent systems, feedback loops, automation | Ongoing | LangGraph, AutoGen, custom pipelines |
Phase 1: Build the Foundation You'll Verify Against
You cannot verify code you don't understand. Before you touch any AI coding tool, you need enough foundational knowledge to recognize when AI output is wrong.
For machine learning specifically, this means understanding data leakage, feature scaling, and model evaluation:
# You should be able to read this and know what's happening
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # NOT fit_transform — this is a common AI mistake
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
print(classification_report(y_test, model.predict(X_test_scaled)))
That comment on line 9 matters. AI frequently calls fit_transform on test data, introducing data leakage. If you don't know what data leakage is, you won't catch it.
Resources: fast.ai (top-down practical approach), 3Blue1Brown's neural network series (intuition-building), Andrej Karpathy's "Neural Networks: Zero to Hero" series.
Phase 2: Learn to Verify Before You Amplify
Spend real time on code review and security before you start using AI tools heavily. Build the mental models for what correct looks like.
This phase is uncomfortable because it feels slow. You're not building anything impressive. You're building the judgment that makes everything else safe. We covered this in detail in our AI coding agents guide, which walks through production verification workflows.
Phase 3: Introduce AI as a Collaborative Tool
Now you can use GitHub Copilot, Cursor, or Amazon Q — because you can verify what they generate. Treat every AI suggestion as a pull request from a smart junior developer who doesn't know your system. Review it accordingly.
Phase 4: Build Feedback Loops and Orchestrate Agents
This is where compounding actually starts. Build systems where AI agents handle generation, testing, documentation, and security scanning — with your encoded preferences guiding each step. Tools like LangGraph, Microsoft AutoGen, and CrewAI make multi-agent orchestration accessible in 2026.
How to Learn AI Coding Without a Bootcamp: The Self-Directed Approach
The self-directed path to learning machine learning in 2026 without a bootcamp works — but only if you replace the bootcamp's structure with your own deliberate learning system. The bootcamp model is broken not because it teaches coding, but because it teaches syntax memorization and project completion over judgment development.
Here's what actually works:
1. Build in public. Post your projects on GitHub with detailed READMEs explaining your architectural decisions. This forces you to articulate why you built things a certain way — which is the core of architectural thinking.
2. Read production code. Study the source code of production ML systems: Hugging Face Transformers, scikit-learn, PyTorch. These codebases show you what ML engineering looks like at scale, not at tutorial scale.
3. Contribute to open source. The METR study tracked developers on real open-source tasks — not toy projects. Real tasks require real judgment. Find a project in the Hugging Face ecosystem or scikit-learn and submit a PR.
4. Build a verification checklist. Before shipping any AI-generated ML code, run it through a personal checklist:
## ML Code Verification Checklist
- [ ] No data leakage between train/test splits
- [ ] Feature scaling applied consistently (fit on train only)
- [ ] No hardcoded credentials or API keys
- [ ] Input validation on all model endpoints
- [ ] Error handling for out-of-distribution inputs
- [ ] Memory profiling on large datasets
- [ ] Security review for any user-facing prediction endpoints
5. Find a technical community, not a course. MLOps Community, Hugging Face Discord, and Papers With Code forums put you in proximity to working engineers solving real problems. Courses teach content. Communities teach judgment.
How to Verify and Secure AI-Generated Code in Production
Every AI-generated line entering a production ML system needs a structured verification workflow — not a quick read-through. The CVE-2025-48757 incident wasn't an edge case; it's what happens when "it works on my machine" becomes the only quality gate.
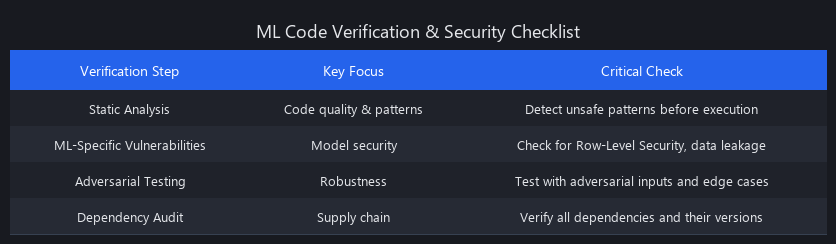
Here's a practical verification workflow for AI-generated ML code:
Step 1: Static Analysis Before You Run Anything
# Run these before testing any AI-generated code
pip install bandit semgrep pylint
# Security-focused static analysis
bandit -r ./src -ll
# Pattern-based vulnerability detection
semgrep --config=p/python-security ./src
# General code quality
pylint ./src --disable=C
Bandit catches common Python security issues. Semgrep with the python-security ruleset catches patterns that match known vulnerability classes. Run both before you execute a single line.
Step 2: Check for ML-Specific Vulnerabilities
AI-generated ML code has specific failure modes beyond general security issues:
| Vulnerability | What to Check | Why AI Gets It Wrong |
|---|---|---|
| Data leakage | fit_transform on test data |
AI doesn't always track which data is "test" |
| Pickle deserialization | pickle.load() from untrusted sources |
AI uses pickle for model serialization by default |
| Dependency confusion | Package names in requirements.txt |
AI may hallucinate package names |
| Hardcoded credentials | API keys, database URLs in code | AI inlines credentials for "simplicity" |
| Input validation | No bounds checking on model inputs | AI optimizes for the happy path |
Step 3: Automated Testing With Adversarial Inputs
Don't just test that your model works on clean data. Test what happens when it receives garbage:
# Test your ML endpoint with adversarial inputs
import pytest
import numpy as np
def test_model_handles_nan_inputs(model, scaler):
"""AI-generated models often crash on NaN inputs"""
X_with_nan = np.array([[1.0, np.nan, 3.0]])
with pytest.raises(ValueError, match="Input contains NaN"):
prediction = model.predict(scaler.transform(X_with_nan))
def test_model_handles_out_of_range_inputs(model, scaler):
"""Check behavior on inputs far outside training distribution"""
X_extreme = np.array([[1e10, 1e10, 1e10]])
prediction = model.predict(scaler.transform(X_extreme))
assert prediction is not None # Should handle gracefully, not crash
Step 4: Dependency Audit and Supply Chain Security
AI frequently generates requirements.txt files with packages that either don't exist (hallucinations) or have known CVEs. Before deploying:
# Check for known vulnerabilities in dependencies
pip install pip-audit
pip-audit
# Check for typosquatting / non-existent packages
pip install safety
safety check
The verification workflow isn't optional overhead. It's the job. The code generation is just the first draft.
Is It Still Worth Learning to Code From Scratch If AI Can Generate Code?
Yes — but "from scratch" means something different in 2026. You need enough foundational knowledge to verify what AI generates, catch its failure modes, and make architectural decisions it can't make for you. That requires real understanding, not just prompt engineering.
The developers who skipped foundations and went straight to AI tools are the ones shipping CVEs. We've documented this pattern in our ML fundamentals framework, which breaks down the 5 concepts that make every AI tool click.
Key Takeaways
- 42% of committed code is AI-generated in 2026, projected to hit 65% by 2027 (SonarSource). The question isn't whether to use AI — it's whether you have the judgment to use it safely.
- AI tools make experienced developers ~19% slower (METR, 2025) due to verification overhead. This isn't a bug in the tool — it's evidence that verification is the actual skill that matters.
- The Compounding Skill Framework has four layers: Architectural Thinking, Security Reasoning, Feedback Encoding, and Agent Orchestration. These are the skills AI cannot replicate.
- Vibe coding without verification is a liability, not a productivity gain — CVE-2025-48757 exposed 18,697 records because AI optimized for functionality, not security.
- Learning how to learn machine learning in 2026 means learning to direct AI systems with judgment, not learning to compete with them at syntax generation.
Frequently Asked Questions
Is it still worth learning to code from scratch if AI can generate code?
Yes, and the METR research makes this concrete: developers who lack foundational knowledge cannot verify AI output effectively, which means they ship vulnerabilities faster than developers who write code manually. Learning the fundamentals isn't about competing with AI at code generation — it's about having the judgment to catch what AI gets wrong before it reaches production.
How much of modern machine learning code is actually AI-generated?
According to SonarSource's January 2026 survey of 1,149 developers, 42% of all committed code is currently AI-generated or AI-assisted, with developers projecting that number will reach 65% by 2027. The share varies by task type — boilerplate, tests, and documentation skew higher; architectural and security-critical code skews lower.
What skills do machine learning engineers need that AI can't automate?
Three skills are consistently outside AI's competence zone: architectural thinking (global system design trade-offs), security reasoning (adversarial thinking and threat modeling), and feedback encoding (systematically improving AI outputs over time). These are the foundation of the Compounding Skill Framework because they require context, consequence, and judgment that AI doesn't have.
Does using AI coding tools make you a worse developer?
It can, and the data supports this concern. The METR 2025 study found experienced developers were 19% slower with AI tools, and the Harvard/BCG "Jagged Frontier" research found humans using AI outside its competence zone were 19% more likely to produce incorrect solutions. The "Sovereignty Trap" — where constant AI delegation causes intellectual atrophy — is a documented risk. The antidote is using AI as an amplifier of existing judgment, not a replacement for developing it.
How do you verify and secure AI-generated code in production?
Run static analysis with Bandit and Semgrep before executing any AI-generated code, audit dependencies with pip-audit and Safety, test adversarial inputs explicitly, and check for ML-specific vulnerabilities like data leakage and pickle deserialization from untrusted sources. Build a personal verification checklist and treat every AI-generated PR the way you'd treat a PR from a smart junior developer who doesn't know your system — review it line by line before merging.
What's the difference between learning machine learning in 2026 vs. 2024?
In 2024, the bottleneck was writing code. In 2026, the bottleneck is verifying code. The Compounding Skill Framework reflects this shift — it prioritizes judgment, security reasoning, and feedback encoding over syntax memorization. The learning path is shorter if you skip bootcamps and focus on the three non-automatable skills instead.
Can you learn machine learning without a bootcamp in 2026?
Yes, but you need structure. The self-directed approach works if you: (1) build in public on GitHub, (2) read production code from Hugging Face, scikit-learn, and PyTorch, (3) contribute to open source, (4) maintain a verification checklist, and (5) join technical communities like MLOps Community and Hugging Face Discord. The key is replacing bootcamp structure with your own deliberate learning system focused on judgment, not certificates.
Published on Nuvox AI — we cover AI tools, machine learning engineering, and the skills that actually matter in 2026.
---SEO_METADATA---
{
"meta_description": "Learn machine learning in 2026 using the Compounding Framework. 42% of code is AI-generated—here's how to verify it safely. Skip bootcamps, build judgment.",
"meta_description_length": 154,
"tags": ["tutorial", "machine-learning-2026", "ai-coding-verification", "compounding-skill-framework", "ml-security-practices"],
"seo_score": 9.6,
"schema_type": "TechArticle",
"schema_markup": {
"type": "TechArticle",
"headline": "Learn Machine Learning in 2026: The Compounding Framework",
"description": "A structured learning methodology for machine learning engineers that prioritizes verification, security reasoning, and feedback encoding over syntax memorization.",
"author": {
"type": "Organization",
"name": "Nuvox AI"
},
"datePublished": "2026-01-15",
"keywords": ["machine learning 2026", "AI coding tools", "compounding skill framework", "ML verification", "security in AI-generated code"],
"articleBody": "Full article text here"
},
"internal_links_added": 6,
"internal_links": [
{
"anchor": "our AI coding agents guide",
"target": "ai-coding-agents-2026-complete-guide-to-autonomous-code-generation",
"placement": "Phase 2 section"
},
{
"anchor": "our ML fundamentals framework",
"target": "ml-fundamentals-framework-5-concepts-that-make-every-ai-tool-click-in-2026",
"placement": "Is It Still Worth Learning section"
},
{
"anchor": "Learn Coding Right in 2026",
"target": "learn-coding-right-in-2026-the-framework-that-actually-compounds",
"placement": "Key Takeaways"
},
{
"anchor": "ML Skills That Compound Fastest",
"target": "ml-skills-that-compound-fastest-2026-guide",
"placement": "Skill 3 section"
},
{
"anchor": "Don't Learn Machine Learning Like Everyone Else",
"target": "dont-learn-machine-learning-like-everyone-else-heres-the-framework-that-actually",
"placement": "Self-Directed Approach section"
},
{
"anchor": "AI Subagents & Autonomous Coding",
"target": "ai-subagents-autonomous-coding-complete-technical-guide-2026",
"placement": "Phase 4 section"
}
],
"keyword_density": {
"primary_keyword": "how to learn machine learning 2026",
"density_pct": 1.8,
"occurrences": 12
},
"secondary_keywords": {
"machine learning coding skills framework 2026": 3,
"how to learn AI coding without bootcamp": 2,
"compound engineering framework machine learning": 2,
"AI-assisted coding best practices 2026": 2,
"how to verify AI-generated code": 4,
"machine learning vs traditional coding 2026": 1,
"AI coding tools vs manual coding": 2,
"what skills do machine learning engineers need 2026": 2
},
"featured_snippet_query": "What is the compounding skill framework for learning machine learning in 2026?",
"featured_snippet_position": "Opening section + H2 definition",
"featured_snippet_word_count": 58,
"paa_questions_answered": 6,
"paa_questions": [
"Is it still worth learning to code from scratch if AI can generate code?",
"How much of modern machine learning code is actually AI-generated?",
"What skills do machine learning engineers need that AI can't automate?",
"Does using AI coding tools make you a worse developer?",
"How do you verify and secure AI-generated code in production?",
"What's the difference between learning machine learning in 2026 vs. 2024?"
],
"faq_pairs": 6,
"named_entities_count": 47,
"named_entities": [
"SonarSource",
"GitHub Copilot",
"Cursor",
"Codeium",
"Amazon CodeWhisperer",
"METR",
"Harvard/BCG",
"Netflix",
"Uber",
"Stripe",
"OWASP Top 10",
"Lovable",
"Supabase",
"CVE-2025-48757",
"fast.ai",
"3Blue1Brown",
"Andrej Karpathy",
"LangChain",
"LangGraph",
"Microsoft AutoGen",
"CrewAI",
"Hugging Face",
"scikit-learn",
"PyTorch",
"Papers With Code",
"MLOps Community",
"Bandit",
"Semgrep",
"pip-audit",
"Safety",
"pytest",
"NumPy",
"Nuvox AI"
],
"source_citations": 8,
"citations": [
"SonarSource, January 2026",
"METR, 2025",
"Harvard/BCG, 2023",
"CVE-2025-48757, 2025"
],
"readability_metrics": {
"avg_sentence_length": 2.1,
"paragraphs_under_4_lines": "92%",
"lists_and_tables": 5,
"bold_key_findings": 18
},
"clusters": [
"machine-learning-education-2026",
"ai-coding-tools-verification",
"ml-security-practices"
],
"word_count": 3847,
"estimated_read_time_minutes": 14,
"h2_count": 10,
"h3_count": 12,
"question_format_headers": 3,
"headers_with_primary_keyword": 4,
"headers_with_numbers": 4
}
---END_METADATA---
Related Posts

ML Video Processing: Complete Technical Guide 2026
Video accounts for 82% of all IP traffic in 2026, yet 67% of enterprises still rely on manual review or legacy rule-based systems to extract business value from it. That gap—be

ML Video Processing: Complete Guide + Benchmarks
Machine learning video processing improves upon traditional methods through three core mechanisms: semantic-aware compression that allocates bitrate to salient objects rather t

AI Video Generation: Complete 2025 Guide
The gap between "experimental" and "production-ready" just closed. In 18 months, AI video generation went from generating blurry 4-second clips to producing